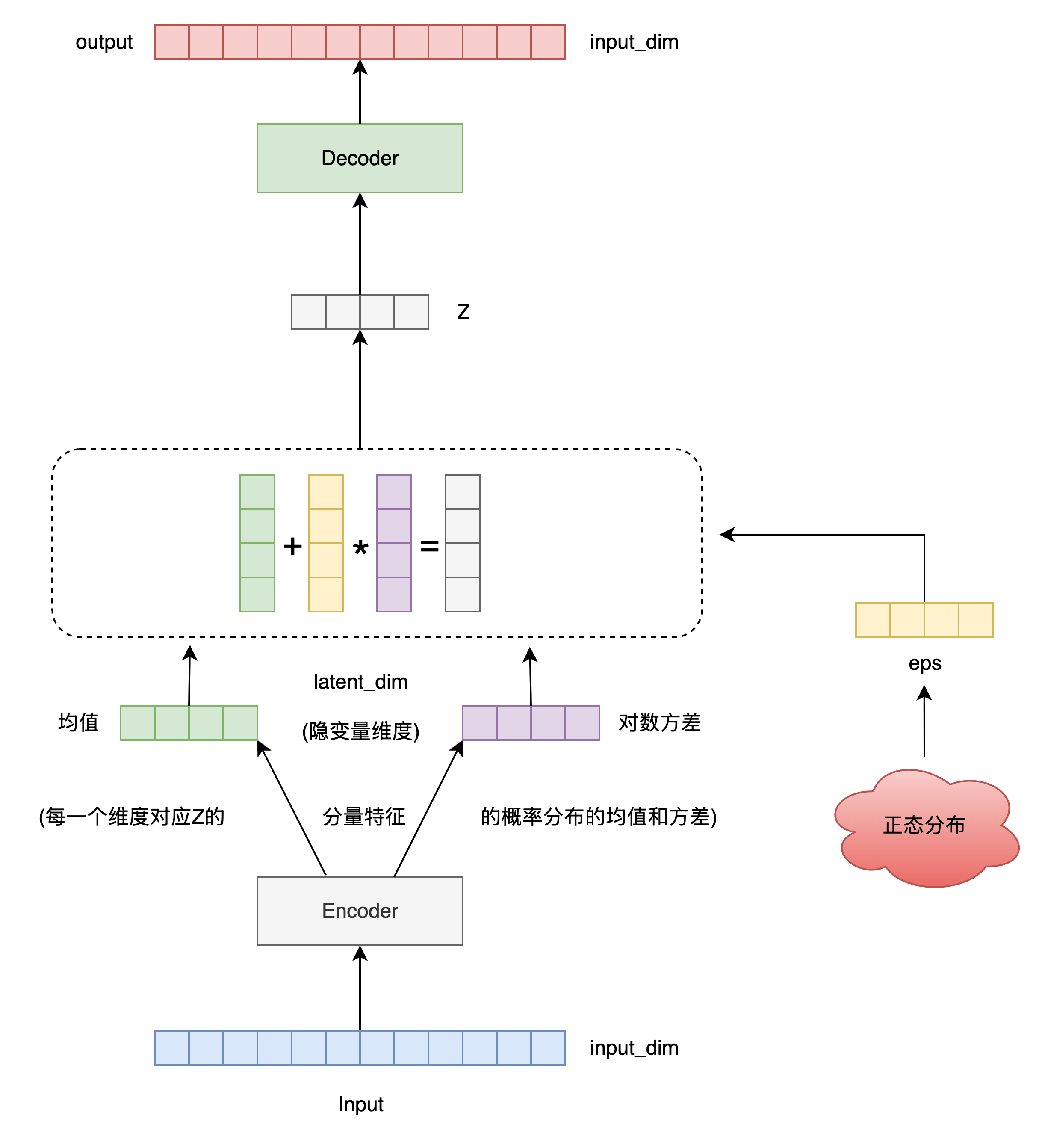
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
| # 导入必要的库
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
from torchvision.utils import save_image
import matplotlib.pyplot as plt
import os
# 1. 配置全局超参数(兼容Python 3.8,参数清晰可调整)
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 优先使用GPU加速
BATCH_SIZE = 128 # 批次大小
EPOCHS = 30 # 训练轮数
LEARNING_RATE = 1e-3 # 学习率
LATENT_DIM = 20 # 潜在变量z的维度(隐空间维度)
IMAGE_SIZE = 784 # MNIST图像展平后的尺寸(28*28)
NUM_CLASSES = 10 # MNIST数据集的类别数(0-9共10个数字)
CONDITION_DIM = 16 # 类别条件的嵌入维度(将类别标签转为固定维度向量)
SAVE_IMAGE_PATH = "./cvae_generated_images/" # 生成图像的存储路径
# 创建生成图像存储目录(不存在则创建,避免文件保存报错)
os.makedirs(SAVE_IMAGE_PATH, exist_ok=True)
# 2. 数据预处理与数据集加载
# 定义数据变换:转为Tensor + 归一化(将像素值从[0,255]映射到[0,1],匹配后续Sigmoid输出)
transform = transforms.Compose([
transforms.ToTensor(), # 转为torch.Tensor,形状为(C,H,W),值范围[0,1]
])
# 加载MNIST训练数据集(自动下载到./data目录,包含图像和对应的类别标签)
train_dataset = datasets.MNIST(
root='./data',
train=True,
download=True,
transform=transform
)
# 构建数据加载器(批量加载数据,自动打乱,num_workers=0适配Python 3.8部分环境)
train_loader = DataLoader(
dataset=train_dataset,
batch_size=BATCH_SIZE,
shuffle=True,
num_workers=0
)
# 3. 定义CVAE模型(包含编码器、解码器、重参数化技巧,核心新增类别条件融入)
class CVAE(nn.Module):
def __init__(self, latent_dim, image_size, num_classes, condition_dim):
super(CVAE, self).__init__()
self.latent_dim = latent_dim
self.image_size = image_size
self.num_classes = num_classes
self.condition_dim = condition_dim
# -------------- 类别标签嵌入层:将离散类别标签转为连续向量(便于与图像/隐变量融合)--------------
# 输入:类别索引(0-9),输出:固定维度的嵌入向量(condition_dim)
self.label_embedding = nn.Embedding(num_classes, condition_dim)
# -------------- 编码器(Encoder):输入「图像+类别条件」-> 隐空间分布参数(μ, log_var)--------------
# 编码器输入维度 = 图像展平维度 + 类别嵌入维度(融合图像信息和类别信息)
encoder_input_dim = image_size + condition_dim
self.encoder = nn.Sequential(
nn.Linear(encoder_input_dim, 512), # 输入层:融合特征 -> 隐藏层(512)
nn.ReLU(inplace=True), # 激活函数:ReLU(加速训练,缓解梯度消失)
nn.Linear(512, 256), # 隐藏层:512 -> 256
nn.ReLU(inplace=True), # 激活函数:ReLU
nn.Linear(256, 2 * latent_dim) # 输出层:256 -> 2*latent_dim(分别对应μ和log_var)
)
# -------------- 解码器(Decoder):输入「隐变量z+类别条件」-> 生成图像--------------
# 解码器输入维度 = 隐变量维度 + 类别嵌入维度(融合隐空间信息和类别信息)
decoder_input_dim = latent_dim + condition_dim
self.decoder = nn.Sequential(
nn.Linear(decoder_input_dim, 256), # 输入层:融合特征 -> 隐藏层(256)
nn.ReLU(inplace=True), # 激活函数:ReLU
nn.Linear(256, 512), # 隐藏层:256 -> 512
nn.ReLU(inplace=True), # 激活函数:ReLU
nn.Linear(512, image_size), # 输出层:512 -> 784(与输入图像尺寸一致)
nn.Sigmoid() # 激活函数:Sigmoid(将输出映射到[0,1],匹配图像像素分布)
)
def encode(self, x, labels):
"""
编码器前向传播:输入「图像+类别标签」-> 隐空间分布参数(μ, log_var)
核心:先将类别标签嵌入,再与图像展平数据拼接,作为编码器输入
"""
# 1. 类别标签嵌入:离散标签 -> 连续向量(形状:[batch_size, condition_dim])
label_emb = self.label_embedding(labels)
# 2. 图像展平:[batch_size, 1, 28, 28] -> [batch_size, 784]
x_flat = x.view(-1, self.image_size)
# 3. 拼接图像特征和类别嵌入特征(维度在第1维拼接,保持批次维度不变)
encoder_input = torch.cat([x_flat, label_emb], dim=1)
# 4. 编码器前向传播,得到输出
h = self.encoder(encoder_input)
# 5. 将输出切分为均值μ和对数方差log_var(各占latent_dim维度)
mu, log_var = torch.chunk(h, 2, dim=1)
return mu, log_var
def reparameterize(self, mu, log_var):
"""
重参数化技巧(核心,与VAE一致):解决隐变量z不可导的问题
思路:不直接从N(μ, σ²)采样z,而是从N(0,1)采样ε,通过z=μ+ε*σ得到z
其中σ=exp(0.5*log_var),这样只有μ和log_var参与梯度传播,ε为常数不参与求导
"""
std = torch.exp(0.5 * log_var) # 计算标准差σ:exp(0.5*log_var)(避免方差为负)
eps = torch.randn_like(std) # 从标准正态分布N(0,1)采样ε,形状与std一致
z = mu + eps * std # 计算最终的可导隐变量z
return z
def decode(self, z, labels):
"""
解码器前向传播:输入「隐变量z+类别标签」-> 生成图像
核心:先将类别标签嵌入,再与隐变量z拼接,作为解码器输入
"""
# 1. 类别标签嵌入:离散标签 -> 连续向量(形状:[batch_size, condition_dim])
label_emb = self.label_embedding(labels)
# 2. 拼接隐变量z和类别嵌入特征(维度在第1维拼接,保持批次维度不变)
decoder_input = torch.cat([z, label_emb], dim=1)
# 3. 解码器前向传播,得到生成图像
return self.decoder(decoder_input)
def forward(self, x, labels):
"""
CVAE整体前向传播(端到端)
"""
# 1. 编码:得到融入类别信息的隐空间分布参数
mu, log_var = self.encode(x, labels)
# 2. 重参数化:得到可导的隐变量z
z = self.reparameterize(mu, log_var)
# 3. 解码:得到融入类别信息的生成图像
x_recon = self.decode(z, labels)
# 返回生成图像、μ、log_var(μ和log_var用于计算损失函数)
return x_recon, mu, log_var
# 4. 定义CVAE损失函数(与VAE一致,包含重构损失和KL散度损失)
def cvae_loss(x_recon, x, mu, log_var):
"""
CVAE损失函数 = 重构损失(Reconstruction Loss) + KL散度损失(KL Divergence Loss)
1. 重构损失:衡量生成图像与原始图像的差异,使用二元交叉熵(BCE)(匹配Sigmoid输出)
2. KL散度损失:衡量隐空间分布N(μ, σ²)与标准正态分布N(0,1)的差异,约束隐空间分布
"""
# 重构损失:二元交叉熵损失(展平后计算,确保维度匹配,reduction='sum'按样本求和)
recon_loss = nn.functional.binary_cross_entropy(
x_recon.view(-1, IMAGE_SIZE), # 生成图像展平:[batch_size, 784]
x.view(-1, IMAGE_SIZE), # 原始图像展平:[batch_size, 784]
reduction='sum'
)
# KL散度损失:计算N(μ, σ²)与N(0,1)的KL散度(推导后的简化公式,避免数值不稳定)
kl_loss = -0.5 * torch.sum(1 + log_var - mu.pow(2) - log_var.exp())
# 总损失 = 重构损失 + KL散度损失(权重均为1,可按需调整平衡生成质量与多样性)
total_loss = recon_loss + kl_loss
return total_loss, recon_loss, kl_loss
# 5. 初始化模型、优化器
model = CVAE(
latent_dim=LATENT_DIM,
image_size=IMAGE_SIZE,
num_classes=NUM_CLASSES,
condition_dim=CONDITION_DIM
).to(DEVICE) # 实例化CVAE模型并移至指定设备(GPU/CPU)
optimizer = optim.Adam(model.parameters(), lr=LEARNING_RATE) # 使用Adam优化器(收敛快,稳定性好)
# 6. 定义训练函数(记录训练误差,每轮生成并保存示例图像)
def train_cvae(model, train_loader, optimizer, epochs, device):
"""
CVAE训练函数:完成模型训练,记录每轮损失,每轮生成示例图像
"""
# 初始化损失记录列表,用于后续可视化训练误差
train_total_losses = []
train_recon_losses = []
train_kl_losses = []
model.train() # 切换模型到训练模式(启用BatchNorm/Dropout等训练相关层,此处无但保持规范)
for epoch in range(epochs):
# 初始化每轮的损失累积变量
epoch_total_loss = 0.0
epoch_recon_loss = 0.0
epoch_kl_loss = 0.0
batch_count = 0
for batch_idx, (data, labels) in enumerate(train_loader):
# 数据预处理:移至指定设备,保持标签为长整型(适配Embedding层输入)
data = data.to(device)
labels = labels.to(device, dtype=torch.long)
# 梯度清零:避免上一批次梯度累积影响当前批次训练
optimizer.zero_grad()
# 前向传播:得到生成图像、μ、log_var
x_recon, mu, log_var = model(data, labels)
# 计算损失:总损失、重构损失、KL散度损失
total_loss, recon_loss, kl_loss = cvae_loss(x_recon, data, mu, log_var)
# 反向传播:计算模型参数梯度
total_loss.backward()
# 梯度更新:更新模型参数
optimizer.step()
# 累积批次损失(转换为numpy值,避免占用GPU内存)
epoch_total_loss += total_loss.item()
epoch_recon_loss += recon_loss.item()
epoch_kl_loss += kl_loss.item()
batch_count += 1
# 计算本轮平均损失(按批次平均,便于跨轮次对比)
avg_total_loss = epoch_total_loss / batch_count
avg_recon_loss = epoch_recon_loss / batch_count
avg_kl_loss = epoch_kl_loss / batch_count
# 记录本轮平均损失,用于后续可视化
train_total_losses.append(avg_total_loss)
train_recon_losses.append(avg_recon_loss)
train_kl_losses.append(avg_kl_loss)
# 打印本轮训练信息(控制台输出,观察训练进度)
print(f"Epoch [{epoch+1}/{epochs}], "
f"Avg Total Loss: {avg_total_loss:.4f}, "
f"Avg Recon Loss: {avg_recon_loss:.4f}, "
f"Avg KL Loss: {avg_kl_loss:.4f}")
# 每轮训练结束后,生成并保存一组示例图像(默认生成0-9每个数字各8张)
generate_and_save_images(model, epoch+1, device, target_digits=None)
# 返回训练损失记录,用于后续可视化
return train_total_losses, train_recon_losses, train_kl_losses
# 7. 定义图像生成与保存函数(支持手动指定生成数字类型,如生成数字2)
def generate_and_save_images(model, epoch, device, target_digits=None, n_samples_per_digit=8):
"""
生成图像并保存到指定路径,支持手动指定生成的数字类型
参数说明:
model: 训练好的CVAE模型
epoch: 训练轮数(用于文件名命名)
device: 计算设备(GPU/CPU)
target_digits: 手动指定的生成数字列表,None则生成0-9所有数字
n_samples_per_digit: 每个数字生成的样本数
"""
model.eval() # 切换模型到评估模式(禁用BatchNorm/Dropout,固定模型参数)
with torch.no_grad(): # 禁用梯度计算(节省内存,加快生成速度,无需求导)
# 1. 确定要生成的数字类别
if target_digits is None:
target_digits = list(range(NUM_CLASSES)) # 默认生成0-9所有数字
else:
# 验证输入的目标数字是否合法(0-9之间的整数)
target_digits = [d for d in target_digits if 0 <= d < NUM_CLASSES]
if not target_digits:
raise ValueError("目标数字必须是0-9之间的整数")
# 2. 构造类别标签(每个数字生成n_samples_per_digit个样本)
labels_list = []
for digit in target_digits:
labels_list.extend([digit] * n_samples_per_digit)
labels = torch.tensor(labels_list, dtype=torch.long).to(device)
# 3. 从标准正态分布采样隐变量z(形状与标签匹配)
z = torch.randn(len(labels), LATENT_DIM).to(device)
# 4. 解码生成图像(融入类别标签信息,得到指定数字的生成图像)
generated_images = model.decode(z, labels).view(-1, 1, 28, 28)
# 5. 保存生成的图像(网格形式,文件名包含轮数/目标数字)
if target_digits is not None and len(target_digits) == 1:
# 单个数字生成:文件名标注具体数字
filename = f"cvae_generated_epoch_{epoch}_digit_{target_digits[0]}.png"
nrow = n_samples_per_digit # 单行显示所有该数字的样本
else:
# 多个数字生成:文件名标注轮数
filename = f"cvae_generated_epoch_{epoch}.png"
nrow = n_samples_per_digit # 每行显示单个数字的所有样本
save_image(
generated_images,
os.path.join(SAVE_IMAGE_PATH, filename),
nrow=nrow, # 网格每行显示的图像数
normalize=False # 无需额外归一化(输出已在[0,1]范围内)
)
model.train() # 切换回训练模式(不影响后续训练,保持规范)
# 8. 启动CVAE模型训练
print("开始训练CVAE模型...")
total_losses, recon_losses, kl_losses = train_cvae(
model=model,
train_loader=train_loader,
optimizer=optimizer,
epochs=EPOCHS,
device=DEVICE
)
# 9. 绘制并展示训练误差曲线(直观观察训练过程中的损失变化)
def plot_training_losses(total_losses, recon_losses, kl_losses):
"""
绘制训练过程中的三种损失曲线:总损失、重构损失、KL散度损失
"""
plt.figure(figsize=(12, 4))
# 绘制总损失曲线
plt.subplot(1, 3, 1)
plt.plot(range(1, EPOCHS+1), total_losses, 'b-', label='Total Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('CVAE Total Training Loss')
plt.legend()
plt.grid(True, alpha=0.3) # 添加网格,提升可读性
# 绘制重构损失曲线
plt.subplot(1, 3, 2)
plt.plot(range(1, EPOCHS+1), recon_losses, 'r-', label='Reconstruction Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('CVAE Reconstruction Training Loss')
plt.legend()
plt.grid(True, alpha=0.3)
# 绘制KL散度损失曲线
plt.subplot(1, 3, 3)
plt.plot(range(1, EPOCHS+1), kl_losses, 'g-', label='KL Divergence Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('CVAE KL Divergence Training Loss')
plt.legend()
plt.grid(True, alpha=0.3)
# 调整子图间距,避免重叠
plt.tight_layout()
# 显示损失曲线窗口
plt.show()
# 调用函数绘制训练误差曲线
plot_training_losses(total_losses, recon_losses, kl_losses)
# 10. 手动指定生成数字类型(示例:生成数字2,可修改为其他数字或多个数字)
print("开始生成指定数字(数字2)的图像...")
generate_and_save_images(
model=model,
epoch="final_target_2",
device=DEVICE,
target_digits=[2], # 手动指定生成数字2,可修改为[0,5,9]等多个数字
n_samples_per_digit=64 # 生成64张数字2的图像,按8×8网格保存
)
# 额外示例:生成数字5和7的图像(可注释掉,按需运行)
# generate_and_save_images(
# model=model,
# epoch="final_target_5_7",
# device=DEVICE,
# target_digits=[5,7],
# n_samples_per_digit=32
# )
print(f"训练与生成完成!所有图像已保存至:{os.path.abspath(SAVE_IMAGE_PATH)}")
|