参数高效微调(PEFT)技术综述
从本章开始,我们将步入对大模型微调的学习。之所以将 PEFT 作为学习的起点,是因为它不仅是当前应对大模型训练高昂成本的主流解决方案,更代表了我们与超大模型互动和应用范式上的一次重要变革。理解 PEFT,是掌握如何在资源有限的条件下,高效、灵活地驾驭大模型强大能力的关键第一步。
一、大模型时代的“微调”困境
自 BERT 模型发布以来,“预训练-微调”(Pre-train and Fine-tune)的范式在自然语言处理领域取得了巨大成功。不过,当模型参数规模从 BERT 的数亿级别跃升至 GPT-3 的千亿级别时,传统的全量微调(Full Fine-Tuning)遇到了挑战:
- 高昂的训练成本:微调一个千亿参数的大模型需要巨大的计算资源(数百 GB 的显存)和时间成本,这对于绝大多数开发者和企业来说是遥不可及的。
- 巨大的存储压力:如果为每一个下游任务都保存一份完整的、千亿级别的模型副本,将导致难以承受的存储开销。
- 灾难性遗忘:在针对特定任务进行微调时,模型很可能会“忘记”在预训练阶段学到的海量通用知识,损害其泛化能力。
- 训练不稳定性:大模型的网络结构“又宽又深”,其训练过程对学习率等超参数极为敏感,很容易出现梯度消失/爆炸等问题,导致训练失败。
面对这些困境,研究者们迫切需要一种新的范式,既能有效利用大模型的强大能力,又能避免全量微调带来的高昂成本。
1.1 “提示”范式的兴起与局限
2020 年 GPT-3 论文带来了一种全新的、无需训练的范式——In-Context Learning 1。研究者们惊喜地发现,在不调整任何模型参数的情况下,仅通过在输入中提供一些任务示例(即 提示 Prompt),就能引导大模型完成特定任务。这一发现迅速催生了“提示工程”(Prompt Engineering)的繁荣。用户通过组合各种关键词、权重和特殊符号,像“炼金术士”一样探索和“召唤”AI 的强大能力。这种人工设计的、离散的文本指令,我们称之为“硬提示”(Hard Prompt)。
但是,“硬提示”这种“刀耕火种”式的方法存在三个明显的局限。找到最优的提示词往往需要大量的试错和经验,过程繁琐且不稳定,充满了“玄学”;离散的文本提示在表达能力上存在上限,难以充分激发和精确控制大模型的潜力;而且在一个模型上精心设计的提示,换到另一个模型或另一种语言上,效果可能大打折扣。
1.2 参数高效微调的诞生
如何找到一种既能有效利用大模型能力,又不必承受全量微调高昂成本的方法?学术界和工业界开始探索一种全新的方法——参数高效微调(Parameter-Efficient Fine-Tuning, PEFT)。
核心思想:冻结(freeze) 预训练模型 99% 以上的参数,仅调整其中极小一部分(通常<1%)的参数,或者增加一些额外的“小参数”,从而以极低的成本让模型适应下游任务。
PEFT 的思想借鉴了计算机视觉领域的迁移学习(Transfer Learning)。在 CV 任务中,我们通常会冻结预训练模型(如 ResNet)负责提取通用特征的卷积层,仅微调后面的全连接层来适应新的分类任务。PEFT 将这一思想应用于 Transformer 架构,并发展出多条技术路线。
二、PEFT 技术发展脉络
2.1 Adapter Tuning
Adapter Tuning 是 PEFT 领域的开创性工作之一,由 Google 在 2019 年为 BERT 模型设计 2。其思路是在 Transformer 的每个块中插入小型的“适配器”(Adapter)模块。如图 11-1 所示,左侧的 Transformer 层展示了 Adapter 模块是如何被集成进去的。Adapter 被插入到每个子层(注意力层和前馈网络)的内部,并与主干网络形成残差连接。在训练时,只有 Adapter 模块的参数会被更新。
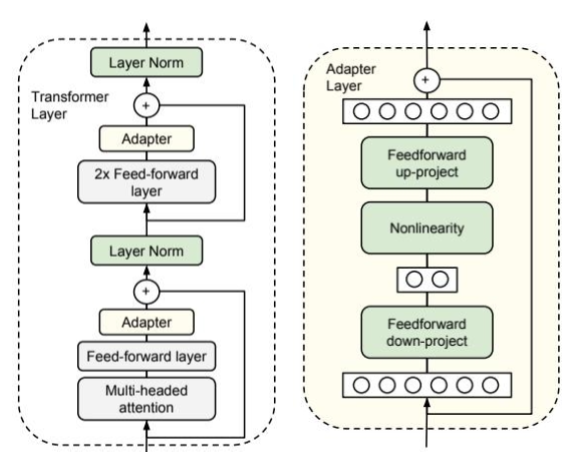
图 11-1 Adapter Tuning 结构
图 11-1 的右侧展示了 Adapter 模块自身的结构,主要包括一个“降维”的全连接层(Feedforward down-project)将高维特征映射到低维空间,一个非线性激活函数(Nonlinearity),一个“升维”的全连接层(Feedforward up-project)再将特征映射回原始维度,以及一个贯穿该模块的残差连接将模块的输出与原始输入相加,保证信息流的稳定。通过这种“瓶颈式”的结构,Adapter 模块可以用极少的参数量来模拟特定任务的知识。这种方法不仅参数效率高、训练稳定,而且性能上能接近全量微调。相比全量微调,能够明显降低可训练参数与优化器状态占用。但由于各层插入了额外模块,训练时仍会带来一定的激活内存与算力开销,在千亿级规模且资源受限的条件下,工程实现更具挑战。
2.2 Prefix Tuning
2021 年,斯坦福大学的研究者提出了 Prefix Tuning,为 PEFT 开辟了一条全新的思路 3。与 Adapter 在模型内部“动手术”不同,Prefix Tuning 选择在模型外部做文章,就像是给模型带上了一张“小抄”。图 11-2 是一个注解示例,揭示了 Prefix Tuning 的工作细节。该图分别展示了 Prefix Tuning 在自回归语言模型(上)和编码器-解码器模型(下)中的应用。它的核心机制在于:
- 前缀激活值(Prefix Activations):图中
PREFIX部分对应的激活值 $h_i$(其中 $i ∈ P_idx$)是从一个专门的可训练矩阵 $P_{\theta}$ 中提取的,这部分参数就是微调的对象。 - 模型计算的激活值: 而原始输入 $x$ 和输出 $y$ 对应的激活值,则是由冻结的 Transformer 模型正常计算得出的。

图 11-2 Prefix Tuning 注解示例
通过这种方式,模型在不改变原有参数的情况下,学会利用这些可控的“前缀”来引导后续内容的生成,从而适应新的任务。同时,为了达到更好的效果,Prefix Tuning 不仅在输入层添加前缀,还在 Transformer 的每一层都添加了对应的可学习 Prefix,并通过一个小型的前馈网络(MLP)来生成这些参数。这种方法的优点是具有较高的参数效率,仅需优化极少数 Prefix 参数而无需改动原模型;它对显存较为友好,因不更新原模型权重,训练时无需维护优化器状态,能显著降低显存与存储开销(尽管需为各层前缀的 K/V 额外预留显存);而且,它的通用性强,在自回归模型(如 GPT-2)和编解码模型(如 T5/BART)上均取得了不错的效果。不过,Prefix Tuning 也存在一些缺点,直接优化 Prefix 向量比微调 Adapter 更困难,训练相对不稳定,对超参数和初始化较为敏感;同时,多数实现将前缀作为各层注意力的额外 K/V 记忆,其长度通常计入注意力配额,可能会减少可用的有效上下文窗口。
2.3 Prompt Tuning
Prefix Tuning 虽然强大,但其复杂的训练过程和在每一层都添加参数的设计,在实践中不够便捷。同年,Google 提出了 Prompt Tuning,可以看作是 Prefix Tuning 的一个简化版 4。这种方法也被称为一种“软提示”。它的做法就是只在输入的 Embedding 层添加可学习的虚拟 Token(称为 Soft Prompt),不再干预 Transformer 的任何中间层。图 11-3 直观地展示了 Prompt Tuning 这种简化思路在实践中所带来的巨大差异,它不仅是参数效率的提升,更在使用范式上迈出了新的一步。
(1)左侧:全量微调:作为性能基准,这种方法遵循“一个任务,一个模型”的模式。针对每一个下游任务(Task A, B, C),都需要用其专属的数据集,对庞大的预训练模型(图中为 110 亿参数)进行完整的微调。最终会得到 N 个与原模型同样大小的任务专属模型副本,导致巨大的存储和部署开销。
(2)右侧:提示微调:它将 PEFT 的效率思想发挥得更加充分,将任务知识完全“外置”到一个轻量级的提示(Prompt)中。实践中可便利地实现混合任务批处理(Mixed-task Batch),便于共享同一冻结模型并提升训练吞吐;多任务训练并非 Prompt Tuning 所独有,但其实现较为简洁。我们可以通过一个具体的例子来理解这个过程:
- 定义任务:假设我们有三个不同的任务类型。
任务 A是情感分析,任务 B是问答,任务 C是 文章摘要。 - 准备数据:
任务 A的一条数据a1可能是一句影评:“这部电影拍得真不错!”。任务 B的数据b1可能是一个问答对:“上下文:‘Datawhale是一个专注于AI与数据科学的开源组织。’ 问题:‘Datawhale是什么?’”。 - 拼接提示进行训练:在训练时,我们会为
a1这条数据前,拼接上专门为“情感分析”任务学习的、可训练的Soft Prompt A。这个Soft Prompt A并非一段人类可读的文本指令(如“请分析情感”),而是一组可通过反向传播优化的、连续的向量(Embeddings)。可以把它理解为一把能解锁大模型特定能力的“钥匙”:在训练时,它可能由“情感”、“正面”、“负面”等词的向量来初始化,并最终被模型自动微调成最优的、能够高效引导模型执行情感分析任务的“虚拟指令”。同理,为b1数据拼接上为“问答”任务学习的Soft Prompt B。如图所示,这些来自不同任务、但都已拼接好各自 Soft Prompt 的数据,可以被组合成一个混合批次,然后一起送入同一个、完全冻结的大语言模型进行训练。模型通过反向传播,只会更新Soft Prompt A和Soft Prompt B的参数,而自身权重保持不变。
结果就是训练对象只是微型的任务提示(参数规模通常为万级,取决于提示长度与嵌入维度),而大模型(11B 参数)始终冻结并被所有任务共享。最终产出的是几个极小的提示文件,而非庞大的模型副本。这种非侵入式的方法实现起来极为简单,达到了很高的参数与存储效率,为实现单一模型服务多种下游任务提供了可能。
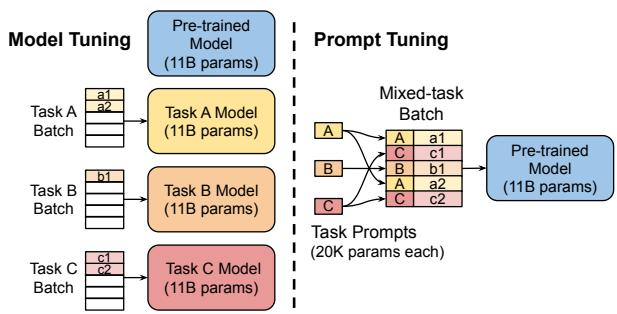
图 11-3 Model Tuning 与 Prompt Tuning 对比
此外,这篇论文最重要的发现是模型规模的缩放效应(The Power of Scale)。如图 11-4 所示,实验表明当模型规模较小(如 1 亿参数)时,Prompt Tuning 的效果(绿线)远不如传统的模型微调(红线和橙线)。但当模型规模超过 100 亿时,Prompt Tuning 的性能开始追平甚至超越全量微调。
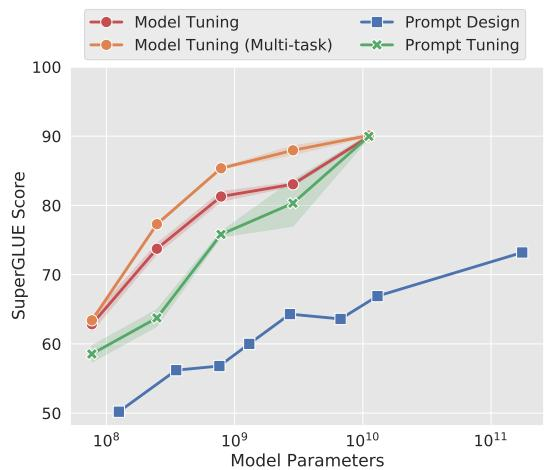
图 11-4 Prompt Tuning 性能与模型规模的关系
这个发现说明只要模型“足够大”,我们就不再需要复杂的、侵入式的微调技术,仅通过学习一个微型的 Soft Prompt,就能让大模型涌现出强大的任务适应能力。然而,这也揭示了 Prompt Tuning 的局限,它的成功强依赖于模型的规模,在中小型模型上效果并不好。
三、P-Tuning v2
Prompt Tuning 虽然足够高效,但它的稳定性较差,且严重依赖超大模型的规模,这限制了其在更广泛场景中的应用。为了解决这些问题,由清华大学团队主导的 P-Tuning 系列工作,对软提示进行了深入优化,最终发展出了效果更强、更通用的 P-Tuning v2。
3.1 P-Tuning 的主要逻辑
为了理解 P-Tuning v2 的精髓,我们首先需要了解其前身 P-Tuning v1。v1 的主要目标是解决离散提示(Discrete Prompts) 的“不稳定性”问题 5。
如图 11-5 所示,P-Tuning v1 将自己与传统的离散提示搜索方法进行了对比:
- (a)离散提示搜索:这类方法试图在离散的文本空间中找到最优的提示词组合。这种搜索过程通常只能依赖离散的奖励信号,优化非常困难且不稳定,找到的解往往是次优的。
- (b)P-Tuning:它提出,不应该在离散空间搜索,而应该在连续空间中进行优化。为此,P-Tuning v1 引入了一个关键组件——Prompt Encoder。它的逻辑是先定义一组可学习的、连续的伪提示(Pseudo Prompts),例如 $[P_0], …, [P_m]$,然后将这些伪提示作为输入,送入一个小型神经网络(如 LSTM)构成的
Prompt Encoder。Prompt Encoder会将这些伪提示编码,捕捉它们之间的依赖关系,并生成最终作为大模型输入的任务相关向量 $h_0, …, h_m$。
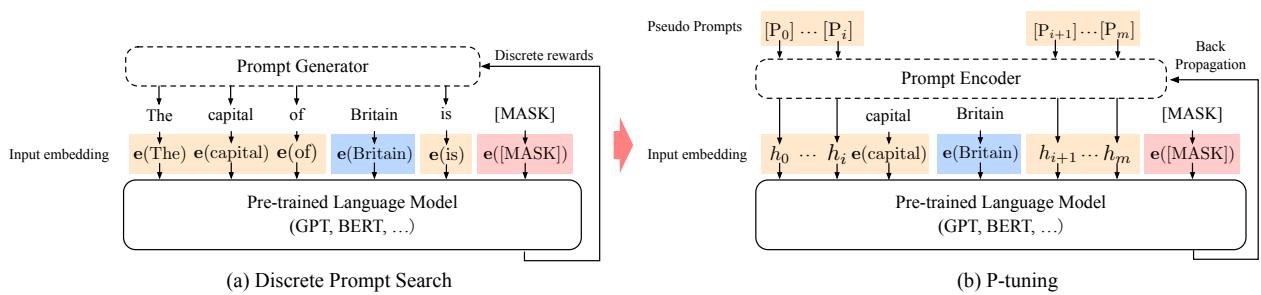
图 11-5 离散提示搜索与 P-Tuning 对比
通过这种方式,Prompt Encoder 及其输入的伪提示,都可以通过反向传播进行端到端的优化。这从根本上改变了寻找最优提示的方式:从“人工试错”变成了可以通过“梯度下降”来自动化求解的数学问题,大幅提升了优化的稳定性和最终效果。我们可以结合上图的具体案例来理解一下。图中展示了一个首都预测任务,输入实体是 “Britain”(英国),目标输出是 “London”(伦敦)。
(1)传统离散提示:我们需要精心设计一个自然语言模板,例如 "The capital of Britain is [MASK]"。
在这个模板中,"The", "capital", "of", "is" 这些词是固定的、离散的 Token。如果我们将模板换成 "Britain's capital city is [MASK]",模型的输出效果可能会发生剧烈变化。这种对提示词的敏感性使得找到“最佳模板”变得很困难。
(2)P-Tuning:P-Tuning 放弃了寻找具体的离散单词,而是引入了一组连续的伪 Token(Pseudo Tokens),我们将其标记为 $[h_0, h_1, …, h_i]$。这时,输入给模型的序列可能变成了这样:
$$[h_0, h_1, ..., h_i], \text{"capital"}, \text{"Britain"}, [h_{i+1}, ..., h_m], \text{[MASK]}$$这里的 $h$ 并不是词表里的某个具体单词,而是可训练的向量参数。在训练开始时,这些向量可能只是随机初始化的,或者用 “The capital of” 对应词向量进行初始化。随后在训练过程中,通过反向传播算法,这些 $h$ 向量会在连续的向量空间中不断调整数值。最终,它们会收敛为一组人类无法直接阅读(因为它们不对应具体的词),但对模型来说最优的提示特征。这组特征能比任何人工设计的离散句子更准确地激发模型输出 “London”。就好比我们不再试图用字典里有限的词汇去拼凑一句“咒语”,而是直接把钥匙(提示向量)打磨成最契合锁孔(模型参数)的形状,以此打开模型知识库的大门。
但是,P-Tuning v1 仍然存在两个问题。它对模型规模较为敏感(在较小模型上收益有限,而在更大模型上更稳定、更具优势),并且在一些复杂的自然语言理解(NLU)任务(特别是序列标注)上表现不佳。
3.2 P-Tuning v2 的演进
2021 年底问世的 P-Tuning v2,就是为了解决 v1 的局限性而设计的 6。它博采众长,吸收了 Prefix Tuning 的思想,最终成为一种在不同模型规模、不同任务上都表现出色的通用 PEFT 方案。
我们可以对照图 11-6,来详细拆解这一演进过程。这张图对比了 P-Tuning v1(图 a)和 P-Tuning v2(图 b)在架构上的本质区别。
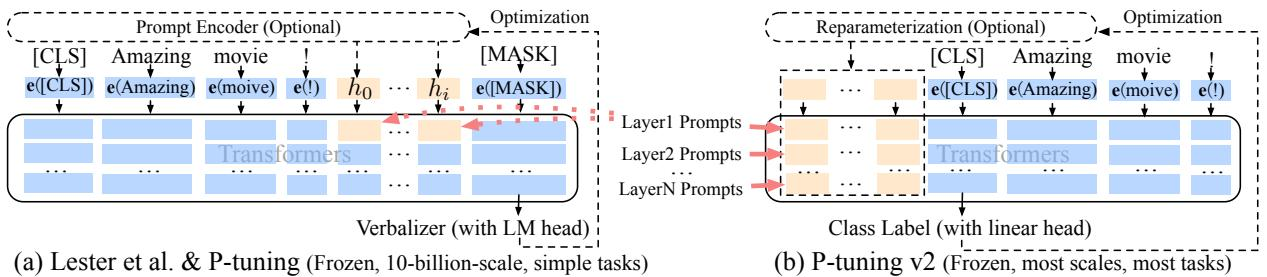
图 11-6 P-Tuning v1 与 P-Tuning v2 的结构对比
(1)P-Tuning v1 的瓶颈:注意图(a)中橙色的提示向量 $h_0, \dots, h_i$ 的位置。
- 浅层提示(Shallow Prompting):提示向量仅被插入到输入层。这意味着提示信息必须经过 Transformer 所有层的层层传递,对模型深层行为的影响力非常有限。也就解释了为什么 P-Tuning v1 和 Prompt Tuning 这类技术在中小规模模型上效果远不如全量微调,往往只有在模型参数规模足够大(具备极强的内在通用能力)时,才能仅靠输入层的微调获得不错的效果。
- 任务局限(Verbalizer):观察输出端的
Verbalizer。第一代技术为了利用预训练目标,强行将所有任务都包装成“完形填空”问题(Masked Language Modeling)。比如做情感分类,必须让模型预测 “good” 或 “bad” 这样的词,再映射回标签。这在处理分类任务时还能应付,但面对序列标注或抽取式阅读理解这种需要对每个 Token 进行细粒度分类的复杂任务时,设计 Verbalizer 就变得极其困难甚至不可能。
(2)P-Tuning v2 的演进:P-Tuning v2 针对上述两个痛点进行了改进,其结构如图(b)所示。
深层提示(Deep Prompting):可以看到图(b)左侧的橙色箭头。提示向量不再只停留在输入层,而是被复制并独立注入到 Transformer 的每一层(Layer 1 Prompts, Layer 2 Prompts…)。这借鉴了 Prefix Tuning 的多层设计。现在,每一层的 Transformer 块都能直接接收到可学习的提示信息。相当于给模型开了“后门”,在每一层都进行直接引导。这种设计大幅增强了提示对模型的控制力。即使是小模型,深层提示也能发挥显著作用。
回归传统分类头(No Verbalizer):我们来看看图(b)下方的输出端,它抛弃了复杂的 Verbalizer,直接换回了传统的
Class Label (with linear head)。既然我们已经通过 Deep Prompting 获得了足够的控制力,就不再需要强行迎合预训练任务了。对于分类或序列标注任务,我们可以直接在最后一层接一个简单的线性层(Linear Head),像传统微调(Fine-tuning)一样直接输出标签。通过这种机制,P-Tuning v2 瞬间拥有了处理复杂任务的能力。它不再受限于“填空题”的格式,可以轻松应用于各类复杂任务。
所以 P-Tuning v2 其实就是做了一个巧妙的融合,包含了 Prefix Tuning 的多层结构 + 传统微调的输出头 + Prompt Tuning 的轻量化。它既保留了 PEFT 参数高效的优势(仅需微调 0.1%~3% 的参数),又找回了全量微调在复杂任务上的通用性和在小模型上的稳定性。
参考文献
Brown, T. B., Mann, B., Ryder, N., et al. (2020). Language Models are Few-Shot Learners. Advances in Neural Information Processing Systems, 33. ↩︎
Houlsby, N., Giurgiu, A., Jastrzebski, S., et al. (2019). Parameter-Efficient Transfer Learning for NLP. Proceedings of the 36th International Conference on Machine Learning. ↩︎
Li, X. L., & Liang, P. (2021). Prefix-Tuning: Optimizing Continuous Prompts for Generation. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics. ↩︎
Lester, B., Al-Rfou, R., & Constant, N. (2021). The Power of Scale for Parameter-Efficient Prompt Tuning. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. ↩︎
Liu, X., Zheng, Y., Du, Z., et al. (2021). GPT Understands, Too. arXiv preprint arXiv:2103.10385. ↩︎
Liu, X., Ji, K., Fu, Y., et al. (2021). P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks. arXiv preprint arXiv:2110.07602. ↩︎