命名实体识别全流程
第一节 命名实体识别概要
一、命名实体识别简介
在上一章节中,我们学习了如何对整个文本进行分类,这是一种对文本的宏观理解。现在,我们将从宏观走向微观,深入文本内部,学习如何精准识别出句子中的人名、地名等具有特定意义的词语或短语,这就是理论部分多次提到的 命名实体识别 (Named Entity Recognition, NER)。作为信息抽取、知识图谱构建、智能问答等众多高级应用的 关键环节,NER的目标是从非结构化文本中,精准地定位并分类出业务所关心的实体对象。
1.1 什么是命名实体?
简单来说,命名实体就是现实世界中事物的名称,是文本中那些指向特定对象、具有可识别性和唯一性的词语或短语。NER 的任务就是将这些“名字”找出来,并贴上预先定义好的标签。常见的实体类型包括:
- 人名 (PER): 姚明, 雷军
- 地名 (LOC): 北京, 故宫
- 组织机构名 (ORG): 阿里巴巴, 英伟达
- 产品名 (PROD): 黑神话:悟空, Blackwell 芯片
- 作品名 (WORK): 三体, 流浪地球
- 其他/杂项 (MISC): 含义依数据集而异(如民族、语言、事件等)
- 时间 (TIME): 昨天, 2025年
一个词是否被视为实体,以及它属于哪种实体,完全由业务场景的需求来决定。例如,在通用的场景下,“苹果”可能只是一个水果;但在数码产品的讨论中,它很可能需要被识别为一个“组织机构名”或“品牌名”。
不同数据集的实体类型定义差异较大(如 CoNLL 2003 仅含 PER/ORG/LOC/MISC;OntoNotes 5 则包含 PERSON、GPE、ORG、FAC、PRODUCT、EVENT、WORK_OF_ART 等更细类别)。实际项目应先明确标签集合。
1.2 NER 的应用价值
如果说 文本分类 是让计算机理解一段话的 主旨大意(比如判断情感是积极还是消极),那么 NER 就是让它更进一步,学会从文本中**“抓住重点”**,精准地找出谁(Who)、在哪(Where)、做了什么(What)等关键信息。这一能力使机器能够“抓住”文本中的关键信息,由此衍生出了更多 NLP 应用:
- 知识图谱构建: 从海量文本中抽取实体及其关系,是构建知识图谱的第一步。
- 信息抽取: 帮助机器从无结构的文本中,整理出结构化的信息。
- 搜索引擎优化: 通过识别查询中的实体,提供更精准、更结构化的搜索结果。
- 智能问答/对话系统: 理解用户意图,从用户的提问中抽取出关键实体,给出准确回答。
以医疗领域为例,NER可以从电子病历、医学文献等海量文本中,像专业医生一样抽取出关键信息,例如“II型糖尿病”等疾病诊断、“多饮”和“多食”等症状描述、“血糖检测”等检查方式,以及“二甲双胍口服”等治疗方案。通过这些抽取出的实体,可以高效地构建医疗知识图谱,为辅助诊断系统、临床研究等提供强大的数据支持。
二、命名实体识别的应用场景
2.1 智能搜索
每当你在搜索引擎中输入问题并立即得到结构化的“知识卡片”时,背后就有 NER 技术在默默工作。一个典型的流程如下:
(1)用户输入 Query:例如,“姚明的身高是多少?”。
(2)Query 理解:后台对 Query 进行分词、词性标注、纠错等基础处理,尝试“读懂”用户的真实意图。这种深度理解通常包括以下两步:
(3)信息检索:根据理解结果,从庞大的知识图谱或索引库中精准匹配答案。
(4)结果排序与呈现:将最相关的结果排序后,以结构化的方式优先呈现给用户。
2.2 聊天机器人与智能辅助诊断
在金融、医疗等特定领域的对话系统中,NER 同样扮演着重要角色。
(1)智能客服:在电商场景下,用户可能会用多种方式咨询同一个问题,例如:
- “我的快递到哪了?”
- “查一下我的订单”
- “我买的东西发货了吗?”
系统无需理解每句话的细微差别,只要通过NER准确识别出用户的核心意图实体“物流信息”,结合用户信息,即可调用订单查询服务,返回最新的物流状态。
(2)智能辅助诊断系统:这是一个多技术融合场景。
三、NER的数据标注
与大多数深度学习任务一样,NER 模型也需要“吃”大量的数据才能学到知识。数据质量在很大程度上决定了模型性能的上限。标注的过程,本质上就是人类在手把手地“教”模型:在给定的文本中,哪些词或短语是什么类型的实体。一份高质量的标注数据集是训练出优秀模型的前提。为了获得高质量的标注数据,业界在实践中探索出了多种不同的标注方法,通常需要在质量成本与效率之间进行权衡:
- 人工标注: 这种方法质量高且可靠,但由于成本高、耗时长,是典型的人力密集型工作。在工具选择上,可以使用简单的 Excel,也可以开发专门的前端标注平台来提高效率。
- 大语言模型辅助标注: 先使用 LLM 对数据进行预标注,然后再由人工进行校对和修正。优点是可以显著提高标注效率,将人的角色从“从零创造”变为“审核修正”。不过,由于 LLM 的输出质量不稳定,所以仍需人工审核以保证数据最终的质量。
- 半监督/迭代式标注: 这是一种不断迭代优化的流程,首先人工标注一小部分数据来训练一个“学生”模型;接着用这个模型去预测大量未标注的数据,然后由人工检查和修正这些预测结果(这通常比从零标注快得多);最后将修正后的数据加入训练集,训练出更强的“学生”模型,并重复以上过程。
四、命名实体识别的实现方法
实现命名实体识别的技术路径多种多样,从简单高效的规则匹配到复杂强大的深度学习模型。选择哪种方法,往往需要在项目初期的效果、成本和开发周期之间做出权衡。下面我们来探讨几种主流的实现方案。
4.1 基于字典和规则匹配
这是最传统和简单的方法。通过维护一个包含各种实体词汇的字典(例如,一个巨大的地名词典),然后在文本中进行字符串匹配。该方法优点是实现简单、速度快,对于特定、封闭领域的实体,准确率可能很高。缺点则是泛化能力差,无法识别字典外的新词(新出现的人名、公司名等),并且规则的维护成本极高。
4.2 序列标注模型
目前常见的 NER 实现方式[1]。它将 NER 任务转化为了一个 序列标注 问题——即为文本序列中的每一个 token(通常是字或词)打上一个预定义的标签。
4.2.1 方案一:Token 级别标签预测 (BMES/BIO)
这种方法为每个 Token 预测其在实体中扮演的角色,是序列标注最经典的思想。
4.2.2 方案二:指针网络与片段网络
这类方法主要是为了解决实体嵌套问题,是当前处理复杂 NER 场景的主流方案之一。
片段网络[2][3]:
指针网络[4]:
思路: 与其为每个 token 打一个固定的 BMES 标签,指针网络的思想是为每个 token 训练多个独立的二分类器,分别判断它是否是“某类实体的开头”以及“某类实体的结尾”。这种方式非常适合作为生成候选片段的第一步。
示例: 对于句子 “来一杯星巴克的美式咖啡”,如果我们想同时识别出“星巴克”(机构名)以及嵌套的“美式”、“咖啡”、“美式咖啡”(产品名),指针网络的输出会是这样:
| Token | is_ORG_start | is_ORG_end | is_PROD_start | is_PROD_end | … |
|---|
| 来 | 0 | 0 | 0 | 0 | … |
| 一 | 0 | 0 | 0 | 0 | … |
| 杯 | 0 | 0 | 0 | 0 | … |
| 星 | 1 | 0 | 0 | 0 | … |
| 巴 | 0 | 0 | 0 | 0 | … |
| 克 | 0 | 1 | 0 | 0 | … |
| 的 | 0 | 0 | 0 | 0 | … |
| 美 | 0 | 0 | 1 | 0 | … |
| 式 | 0 | 0 | 0 | 1 | … |
| 咖 | 0 | 0 | 1 | 0 | … |
| 啡 | 0 | 0 | 0 | 1 | … |
候选生成: 得到预测后,后处理程序会按实体类型分别进行“开头-结尾”配对:
通过这种“判断边界,再组合配对”的方式,指针网络巧妙地生成了所有可能的实体片段(包括嵌套的),为后续的分类环节提供了高质量的候选。
指针网络 + 片段网络[5]:
- 思路: 结合两者的长处,形成一个高效的两阶段流程。
- 候选生成 (指针网络): 先使用指针网络高效地预测出所有可能的实体“开头”和“结尾”。
- 候选组合: 将所有合法的“开头-结尾”配对,组合成候选实体片段。这个过程极大地减少了候选片段的数量,过滤掉了绝大多数无意义的组合。
- 候选分类 (片段网络): 再使用片段网络对这些数量大大减少的 候选片段 进行分类。
- 优点: 既能解决嵌套问题,又有效降低了计算量,是解决复杂 NER 问题的有效方案。
4.2.3 方案三:基于分词的分类
4.3 生成式模型
随着大语言模型的发展,也可以将 NER 任务统一到生成框架下,通过精心设计的 Prompt 来“指令”模型完成任务。
五、项目实现思路
在第七章中,我们已经学习并实践了文本分类任务,并了解了 NLP 项目的通用流程。命名实体识别作为另一项 NLP 任务,其项目实现思路在宏观上遵循着相同的流程。在深入探讨具体代码实现之前,本章将再次遵循 数据处理 -> 模型构建 -> 训练、评估与持久化 这套标准流程,勾勒出一个标准 NER 项目的实现思路。
5.1 数据处理与增强
作为模型训练的起点,数据质量在很大程度上决定了模型性能的上限。
在医疗等强约束领域做“实体替换”时,应确保替换后的样本不破坏实体间的真实语义关系(如疾病-症状-药物的搭配约束),否则可能引入反效果。
5.2 模型构建与迁移学习
NER 模型的经典组合一般是 Embedding层 + 动态词向量编码器 (如BERT, Bi-LSTM等) + Token分类层 (如全连接层+Softmax/CRF)。在输入与输出方面,模型输入形状通常为 [N, T] 的 Tensor(其中 N 是批次大小 Batch Size,T 是序列长度 Sequence Length),内容是 Token ID;模型输出形状则为 [N, T, num_classes] 的 Tensor,代表每个 Token 在所有 num_classes 个类别上的置信度得分。
在迁移学习与微调的实践中,通常使用在通用领域预训练好的模型作为初始化参数。常见的微调策略有四种:一是冻结参数,即将预训练模型参数冻结(requires_grad = False),只训练自己新增的分类层,速度快但效果可能受限;二是同等处理,将迁移过来的参数和新增的参数视为一体,使用相同的学习率和更新逻辑进行训练;三是差分学习率微调,为迁移过来的参数设置一个非常小的学习率进行“微调”,使其在保留通用知识的基础上向新任务靠近,同时为新增的参数设置一个正常的学习率使其能快速收敛;四是分层冻结/部分冻结,例如仅冻结 BERT 的前若干层,让后几层与分类头共同更新,这在算力有限或数据较少时常是较好的折中。
5.3 训练、评估与持久化
这是连接数据和模型,产出最终模型的重要循环。
第二节 NER 项目的数据处理
在上一节,我们简单了解了命名实体识别的任务定义、应用场景及主流实现方法。本节将正式进入编码阶段,从数据处理开始,逐步构建一个完整的 NER 项目。为了清晰地构建 NER 的处理流程,我们采用流程化的代码组织思路,将整个流程拆分为多个独立的脚本。
本章全部代码
一、数据处理流程总览
在 NLP 中,原始的文本和标注数据是无法直接被神经网络模型利用的。需要将这些原始数据转换成模型能够理解的、标准化的数字张量。那么,具体要转换成什么样?又该如何转换?这就是本节数据处理流程要解决的问题。
1.1 明确数据处理的目标
在设计之前,我们需要先明确最终的目标。对于一个命名实体识别任务,数据处理需要产出什么?
- 模型的输入 (X) 是什么?
- 它应该是一个整数张量,形状为
[batch_size, seq_len]。 - 其中
batch_size 是批次大小,seq_len 是序列长度(通常是批次内最长句子的长度)。 - 张量中的每一个数字,都代表原始句子中一个字符(Token)在词汇表里对应的唯一 ID。
- 模型的标签 (Y) 是什么?
- 它也应该是一个整数张量,形状与输入 X 完全相同,即
[batch_size, seq_len]。 - 其中的每一个数字,代表着对应位置字符的实体标签 ID(例如,
B-bod 对应的 ID)。
- 如何实现从“文本”到“ID”的转换?
- 文本 -> Token ID:需要构建一个 “字符-ID” 的映射表,也就是词汇表 (Vocabulary)。
- 实体 -> 标签 ID:需要构建一个 “标签-ID” 的映射表。
1.2 数据格式解析
我们使用的是 CMeEE-V2(中文医学实体抽取)数据集。经过分析,该数据集采用的是标准的 JSON 数组 格式。
1.2.1 原始数据示例
打开 CMeEE-V2_train.json,可以看到文件内容是一个完整的 JSON 数组:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| [
...,
{
"text": "(2)室上性心动过速可用常规抗心律失常药物控制,年龄小于5岁。",
"entities": [
{
"start_idx": 3,
"end_idx": 9,
"type": "dis",
"entity": "室上性心动过速"
},
{
"start_idx": 14,
"end_idx": 20,
"type": "dru",
"entity": "抗心律失常药物"
}
]
},
...
]
|
1.2.2 字段说明
text:原始文本字符串
entities
:实体标注列表,每个实体包含:
start_idx:实体起始位置(包含)end_idx:实体结束位置(包含)type:实体类型(如 dis 疾病、dru 药物)entity:实体文本(用于验证)
索引的包含性
对于当前 data/ 目录下的数据,经实测:start_idx 与 end_idx 均为包含(闭区间)。实体应由 text[start_idx : end_idx + 1] 取得。例如:
- 文本:"(2)室上性心动过速可用常规抗心律失常药物控制,年龄小于5岁。”
- 实体 “室上性心动过速”:
start_idx=3, end_idx=9 - 实际字符:
text[3:10] = “室上性心动过速”
所以,实体长度 = end_idx - start_idx + 1。
二、构建标签映射
目标:从原始数据中提取所有实体类型,然后基于 BMES 标注方案构建一个全局统一的“标签-ID”映射表。
2.1 加载数据
在处理任何数据之前,首要需要把它加载到内存里。
2.1.1 调试观察数据结构
开始的代码很简单,我们需要先读取文件并加载其内容。
1
2
3
4
5
6
7
8
9
| import json
def collect_entity_types_from_file(file_path):
with open(file_path, 'r', encoding='utf-8') as f:
all_data = json.load(f) # 下断点
if __name__ == '__main__':
train_file = './data/CMeEE-V2_train.json'
collect_entity_types_from_file(train_file)
|
操作指引:
如 图 2.1 所示,本次调试过程分为三步:
- 设置断点:在代码行
all_data = json.load(f) 左侧的行号旁边单击,设置一个断点。 - 启动调试:点击 PyCharm 右上角的“Debug”按钮(绿色甲虫图标),以调试模式运行当前脚本。程序会自动执行到断点所在行并 暂停,此时
all_data 变量还未被赋值。 - 单步执行 (Step Over):点击调试控制台中的“Step Over”按钮。此操作会执行当前行代码。执行后,
all_data 变量才会被成功赋值。
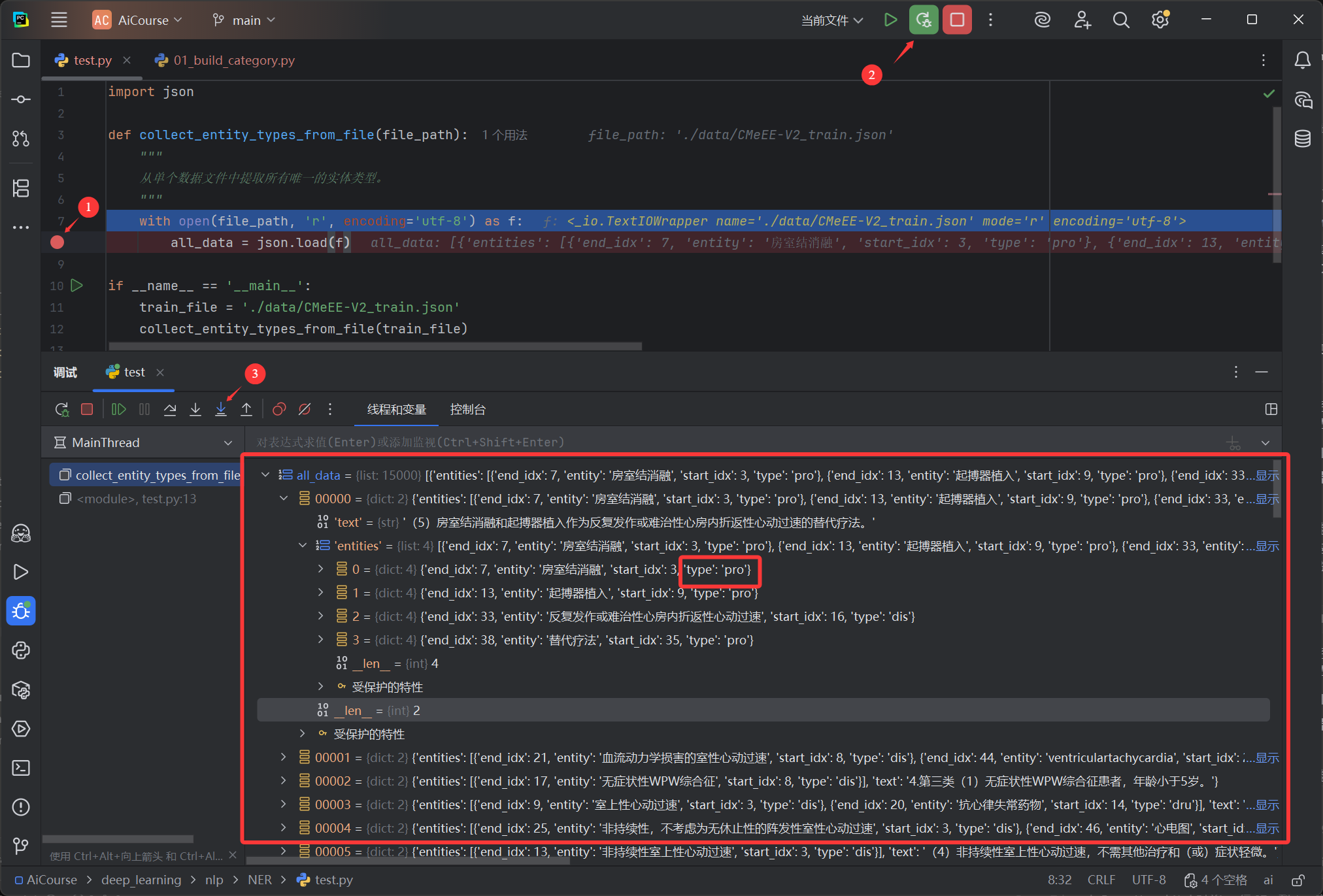
图 2.1: PyCharm 调试器观察数据结构
完成以上步骤后,可以在下方的“Debug”工具窗口中展开 all_data 变量,从而审查其内部结构。通过观察 图 2.1,可以得出结论:
all_data 是一个 list(列表)。- 列表中的每一个元素都是一个
dict(字典),代表一条标注数据。 - 每个字典都包含
text 和 entities 两个键。
以上步骤以 PyCharm 为例,但其调试逻辑(设置断点、启动调试、单步执行)在 VS Code 等其他主流 IDE 中是完全通用的。
刚刚我们通过断点调试,清楚地看到了 all_data 的内部结构,这为编写后续的遍历代码提供了依据。请记住这种方法,后续学习中如果遇到任何不理解的代码或不清楚的变量,都可以使用同样的方式:“哪里不会 D 哪里😉”。
2.1.2 提取实体类型
既然已经清楚了数据结构,现在要做的就是遍历这个列表,从每个字典中提取出我们真正关心的信息——实体类型。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| import json
def collect_entity_types_from_file(file_path):
types = set()
with open(file_path, 'r', encoding='utf-8') as f:
all_data = json.load(f)
for data in all_data:
# 遍历实体列表,提取 'type' 字段
for entity in data['entities']:
types.add(entity['type'])
return types
if __name__ == '__main__':
train_file = './data/CMeEE-V2_train.json'
entity_types = collect_entity_types_from_file(train_file)
print(f"从 {train_file} 中提取的实体类型: {entity_types}")
|
运行结果:
1
| 从 ./data/CMeEE-V2_train.json 中提取的实体类型: {'dru', 'dep', 'dis', 'bod', 'mic', 'equ', 'sym', 'pro', 'ite'}
|
2.2 处理多个文件并保证顺序
下一步需要完成两件事:
- 处理所有的数据文件(训练集、验证集),以确保包含了全部的实体类型。
- 对提取出的实体类型进行排序,以保证每次生成的标签 ID 映射都是完全一致的。
基于此,对代码进行扩展:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| # (collect_entity_types_from_file 函数保持不变,此处省略)
# ...
def generate_tag_map(data_files):
all_entity_types = set()
for file_path in data_files:
types_in_file = collect_entity_types_from_file(file_path)
all_entity_types.update(types_in_file)
# 排序,保证每次运行结果一致
sorted_types = sorted(list(all_entity_types))
# 后续将在这里构建 BMES 映射
# ...
if __name__ == '__main__':
train_file = './data/CMeEE-V2_train.json'
dev_file = './data/CMeEE-V2_dev.json'
generate_tag_map(data_files=[train_file, dev_file])
|
2.3 构建 BMES 标签映射
有了排序后的实体类型列表,就可以构建最终的 tag_to_id 映射字典了。规则如下:
- 非实体标签
'O' 的 ID 为 0。 - 对于每一种实体类型(如
dis),都生成 B-dis, M-dis, E-dis, S-dis 四种标签,并按顺序赋予递增的 ID。
1
2
3
4
5
6
7
8
9
10
11
12
13
| # ... (在 generate_tag_map 函数内部) ...
# ... (汇总和排序逻辑) ...
sorted_types = sorted(list(all_entity_types))
# 构建 BMES 标签映射
tag_to_id = {'O': 0} # 'O' 代表非实体
for entity_type in sorted_types:
for prefix in ['B', 'M', 'E', 'S']:
tag_name = f"{prefix}-{entity_type}"
tag_to_id[tag_name] = len(tag_to_id)
print(f"\n已生成 {len(tag_to_id)} 个标签映射。")
|
2.4 封装与保存
为了让这个映射表能够被其他脚本方便地使用,需要将它保存成一个 JSON 文件。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| def save_json(data, file_path):
os.makedirs(os.path.dirname(file_path), exist_ok=True)
with open(file_path, 'w', encoding='utf-8') as f:
json.dump(data, f, ensure_ascii=False, indent=4)
def collect_entity_types_from_file(file_path):
# ... (函数已在前面定义,此处省略)
def generate_tag_map(data_files, output_file): # 添加 output_file 参数
# 1. 汇总所有实体类型 ...
# 2. 排序以保证映射一致性 ...
# 3. 构建 BMES 标签映射 ...
# 4. 保存映射文件
save_json(tag_to_id, output_file)
print(f"标签映射已保存至: {output_file}")
if __name__ == '__main__':
train_file = './data/CMeEE-V2_train.json'
dev_file = './data/CMeEE-V2_dev.json'
output_path = './data/categories.json'
generate_tag_map(data_files=[train_file, dev_file], output_file=output_path)
|
通过这样一步步的迭代和完善,我们从一个基础的思路,最终构建出了一个可复用的预处理脚本。
2.5 运行结果
执行最终的 01_build_category.py 脚本,会生成 categories.json 文件,内容如下(部分展示):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| {
"O": 0,
"B-bod": 1,
"M-bod": 2,
"E-bod": 3,
"S-bod": 4,
"B-dep": 5,
"M-dep": 6,
"E-dep": 7,
"S-dep": 8,
"B-dis": 9,
"M-dis": 10,
"E-dis": 11,
"S-dis": 12,
...
}
|
三、构建词汇表
有了标签映射,我们还需要创建一个“字符-ID”的映射表(即词汇表),为后续将文本转换为数字序列做准备。
3.1 统计所有字符
目前的首要任务是获取数据中出现的所有字符。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| from collections import Counter
import json
def create_char_vocab(data_files):
char_counts = Counter()
with open(data_files, 'r', encoding='utf-8') as f:
all_data = json.load(f)
for data in all_data:
char_counts.update(list(data['text']))
print(f"初步统计的字符种类数: {len(char_counts)}")
if __name__ == '__main__':
train_file = './data/CMeEE-V2_train.json'
create_char_vocab(train_file)
|
3.2 文本规范化
在检查初步统计的字符时,会发现一个问题。数据中可能同时包含 全角字符(如 ,,()和 半角字符(如 ,,()。它们在语义上相同,但会被视为两个不同的 token(如图 2.2 所示)。
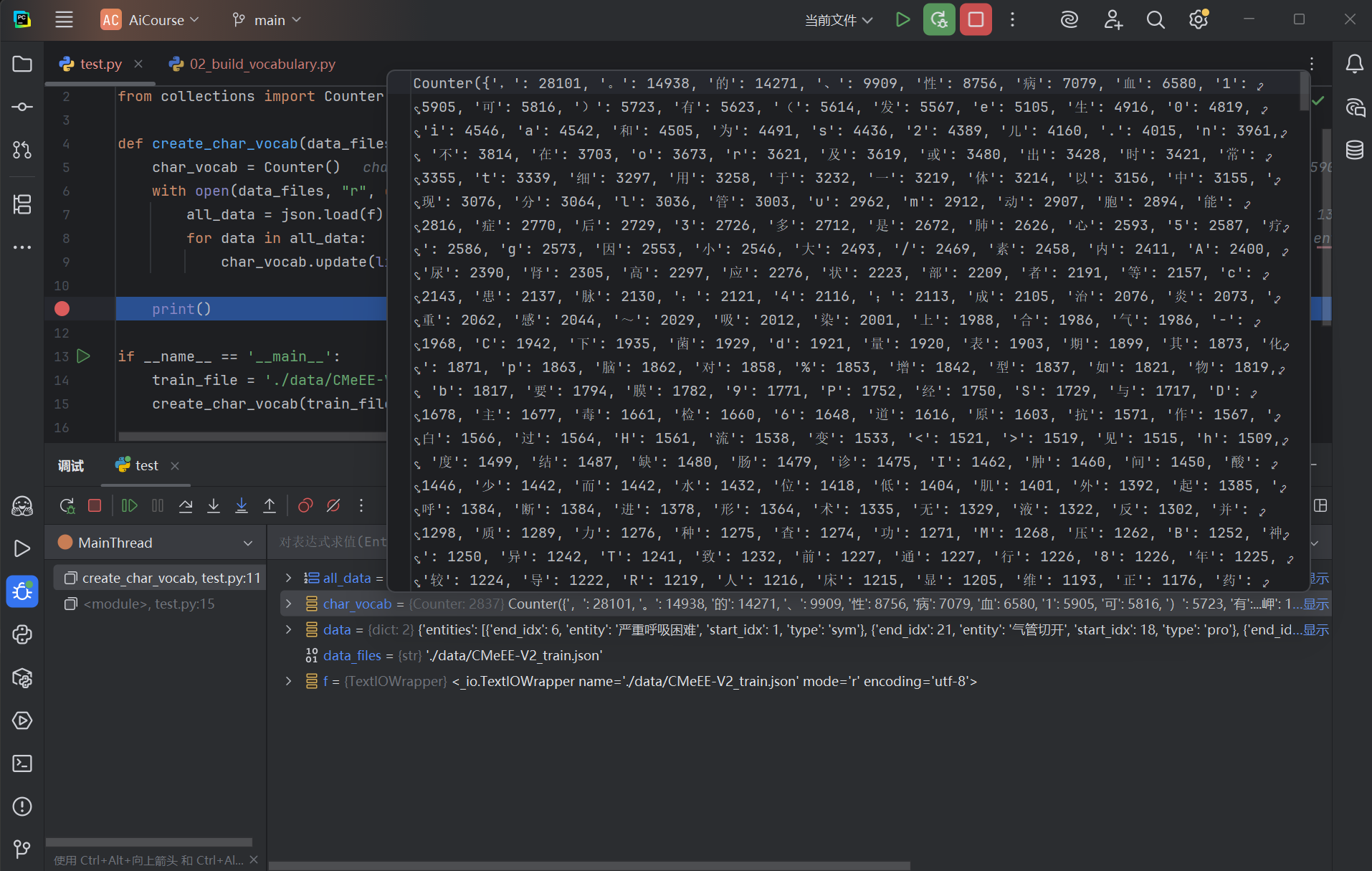
图 2.2: 全角/半角字符混用
为了减小词汇表规模并提升模型泛化能力,可以将它们统一。这里我们直接将所有全角字符转换为半角字符。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| def normalize_text(text):
"""
规范化文本
"""
full_width = "0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz!#$%&’()*+,-./:;<=>?@[\]^_`{|}~""
half_width = r"0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz!#$%&'" + r'()*+,-./:;<=>?@[\]^_`{|}~".'
mapping = str.maketrans(full_width, half_width)
return text.translate(mapping)
def create_char_vocab(data_files):
char_counts = Counter()
with open(data_files, 'r', encoding='utf-8') as f:
all_data = json.load(f)
for data in all_data:
# 在统计前先进行规范化
normalized_text = normalize_text(data['text'])
char_counts.update(list(normalized_text))
print(f"初步统计的字符种类数: {len(char_counts)}")
|
3.3 过滤、排序与添加特殊符
接下来,进行收尾工作:
- 过滤低频词:可以设定一个阈值
min_freq,移除出现次数过少的罕见字,以进一步精简词汇表。 - 排序:与标签映射一样,对最终的字符列表进行排序,确保每次生成的词汇表文件内容完全一致。
- 添加特殊 Token:在列表的最前面,加入两个特殊的标记:
<PAD>(用于后续对齐序列)和 <UNK>(用于表示词汇表中不存在的未知字符)。
3.4 封装与保存
将以上所有逻辑整合,并加入保存文件的功能,便得到了最终的脚本。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
| # ...
def save_json(data, file_path):
# ... (函数与上个脚本中相同,此处省略)
def normalize_text(text):
# ... (函数已在前面定义,此处省略)
def create_char_vocab(data_files, output_file, min_freq=1):
# 1. 统计规范化后的字符频率
char_counts = Counter()
for file_path in data_files:
with open(file_path, 'r', encoding='utf-8') as f:
all_data = json.load(f)
for data in all_data:
text = normalize_text(data['text'])
char_counts.update(list(text))
# 2. 过滤低频词
frequent_chars = [char for char, count in char_counts.items() if count >= min_freq]
# 3. 排序
frequent_chars.sort()
# 4. 添加特殊标记
special_tokens = ["<PAD>", "<UNK>"]
final_vocab_list = special_tokens + frequent_chars
print(f"词汇表大小 (min_freq={min_freq}): {len(final_vocab_list)}")
# 5. 保存词汇表
save_json(final_vocab_list, output_file)
print(f"词汇表已保存至: {output_file}")
if __name__ == '__main__':
train_file = './data/CMeEE-V2_train.json'
dev_file = './data/CMeEE-V2_dev.json'
output_path = './data/vocabulary.json'
create_char_vocab(data_files=[train_file, dev_file], output_file=output_path, min_freq=1)
|
四、封装数据加载器
现在有了标签映射和词汇表,最后一步就是构建一个可复用的 DataLoader,将文本数据高效地转换成 PyTorch 模型能够理解的格式。直接用循环读取数据并手动转换是低效且不灵活的。一个合格的数据加载器需要解决自动批量化、序列填充、数据转换和随机化这几个问题。
所以我们将整个流程拆分为以下几个步骤来逐步实现:
- 步骤一:封装
Vocabulary 类,专门负责 Token 和 ID 之间的转换。 - 步骤二:创建
NerDataset,继承自 PyTorch 的 Dataset,负责处理单个数据样本的转换。 - 步骤三:定义
collate_fn 函数,负责将多个样本打包、填充成一个 batch。 - 步骤四:整合所有组件,创建一个
DataLoader 实例并进行测试。
4.1 封装 Vocabulary 类
第一步,创建一个 Vocabulary 类来加载之前生成的 vocabulary.json,并提供方便的查询接口。这个类主要负责 Token 和 ID 之间的转换。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| import json
class Vocabulary:
"""
负责管理词汇表和 token 到 id 的映射
"""
def __init__(self, vocab_path):
with open(vocab_path, 'r', encoding='utf-8') as f:
self.tokens = json.load(f)
self.token_to_id = {token: i for i, token in enumerate(self.tokens)}
self.pad_id = self.token_to_id['<PAD>']
self.unk_id = self.token_to_id['<UNK>']
def __len__(self):
return len(self.tokens)
def convert_tokens_to_ids(self, tokens):
return [self.token_to_id.get(token, self.unk_id) for token in tokens]
if __name__ == '__main__':
vocab_file = './data/vocabulary.json'
vocabulary = Vocabulary(vocab_path=vocab_file)
print(f"词汇表大小: {len(vocabulary)}")
|
4.2 创建 NerDataset
现在要创建的是核心的数据集类,它继承了 torch.utils.data.Dataset。负责将单条原始数据转换为模型所需的 token_ids 和 label_ids。可以把它想象成一个数据处理的“单件工厂”,DataLoader 每次需要数据时,都会向这个工厂索要一件(__getitem__)加工好的产品。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
| # ...
from torch.utils.data import Dataset
# ... (需要 normalize_text 函数) ...
class Vocabulary:
# ... (类已在前面定义,此处省略)
class NerDataset(Dataset):
def __init__(self, data_path, vocab: Vocabulary, tag_map: dict):
# 一次性将整个 JSON 文件(一个大列表)读入内存
self.vocab = vocab
self.tag_to_id = tag_map
with open(data_path, 'r', encoding='utf-8') as f:
self.records = json.load(f)
def __len__(self):
return len(self.records)
def __getitem__(self, idx):
# 1. 根据索引获取原始记录
record = self.records[idx]
text = normalize_text(record['text'])
tokens = list(text)
# 2. 将文本字符转换为 token_ids
token_ids = self.vocab.convert_tokens_to_ids(tokens)
# 3. 生成与文本等长的 tag 序列,默认为 'O'
tags = ['O'] * len(tokens)
# 4. 遍历实体列表,用 BMES 标签覆盖默认的 'O'
for entity in record.get('entities', []):
entity_type = entity['type']
start = entity['start_idx']
end = entity['end_idx'] # 闭区间结束索引
if end >= len(tokens): continue
if start == end:
tags[start] = f'S-{entity_type}' # 单字实体
else:
tags[start] = f'B-{entity_type}' # 实体开始
tags[end] = f'E-{entity_type}' # 实体结束
for i in range(start + 1, end):
tags[i] = f'M-{entity_type}' # 实体中间
# 5. 将 BMES 标签字符串序列转换为 label_ids
label_ids = [self.tag_to_id[tag] for tag in tags]
# 6. 返回包含两个 Tensor 的字典
return {
"token_ids": torch.tensor(token_ids, dtype=torch.long),
"label_ids": torch.tensor(label_ids, dtype=torch.long)
}
if __name__ == '__main__':
# 为测试 NerDataProcessor 准备所需的 vocab 和 tag_map
vocab_file = './data/vocabulary.json'
categories_file = './data/categories.json'
train_file = './data/CMeEE-V2_train.json'
vocabulary = Vocabulary(vocab_path=vocab_file)
with open(categories_file, 'r', encoding='utf-8') as f:
tag_map = json.load(f)
# 创建数据集实例
train_dataset = NerDataset(train_file, vocabulary, tag_map)
print(f"数据集大小: {len(train_dataset)}")
|
4.3 整合为 DataLoader
最后,定义 create_ner_dataloader 函数。它接收 Dataset 实例,并将其封装成一个 DataLoader。在 NLP 任务中,由于每个样本(句子)的长度都不同,所以不能直接让 DataLoader 使用默认的方式打包数据,否则会因序列长度不一而报错。因此,我们需要提供一个自定义的 collate_fn (校对函数) 来解决这个问题。
collate_fn 的主要任务,就是将从 Dataset 中取出的、由多条数据组成的列表(batch),“聚合”成一个统一的、规整的批次。在当前任务中,它主要负责两件事:
- 动态填充 (Padding):找到当前批次中最长的序列,并将这个批次内的所有样本都填充到这个最大长度。
- 生成 Attention Mask:创建一个
mask 矩阵,用来标记哪些是真实的 Token (值为 1),哪些是填充的 Token (值为 0)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
| # ...
from torch.utils.data import Dataset, DataLoader
from torch.nn.utils.rnn import pad_sequence
# ... (省略前面所有的类和函数定义) ...
def create_ner_dataloader(data_path, vocab, tag_map, batch_size, shuffle=False):
dataset = NerDataset(data_path, vocab, tag_map)
def collate_batch(batch):
token_ids_list = [item['token_ids'] for item in batch]
label_ids_list = [item['label_ids'] for item in batch]
padded_token_ids = pad_sequence(token_ids_list, batch_first=True, padding_value=vocab.pad_id)
padded_label_ids = pad_sequence(label_ids_list, batch_first=True, padding_value=-100)
attention_mask = (padded_token_ids != vocab.pad_id).long()
return {
"token_ids": padded_token_ids,
"label_ids": padded_label_ids,
"attention_mask": attention_mask
}
return DataLoader(
dataset,
batch_size=batch_size,
shuffle=shuffle,
collate_fn=collate_batch
)
if __name__ == '__main__':
# 文件路径
train_file = './data/CMeEE-V2_train.json'
vocab_file = './data/vocabulary.json'
categories_file = './data/categories.json'
# 1. 加载资源
vocabulary = Vocabulary(vocab_path=vocab_file)
with open(categories_file, 'r', encoding='utf-8') as f:
tag_map = json.load(f)
# 2. 创建 DataLoader
train_loader = create_ner_dataloader(
data_path=train_file,
vocab=vocabulary,
tag_map=tag_map,
batch_size=4,
shuffle=True
)
# 3. 验证一个批次的数据
batch = next(iter(train_loader))
print("\n--- DataLoader 输出验证 ---")
print(f" Token IDs shape: {batch['token_ids'].shape}")
print(f" Label IDs shape: {batch['label_ids'].shape}")
print(f" Attention Mask shape: {batch['attention_mask'].shape}")
|
torch.utils.data.DataLoader 是 PyTorch 的核心数据加载工具,它像一个高度自动化的“数据供应管道”。将 NerDataProcessor 实例(dataset)作为数据源传入,并配置了几个关键参数:
batch_size:定义了每个批次包含多少样本。shuffle=True:使得加载器在每个 epoch 开始时都随机打乱数据顺序,能有效提升泛化能力。collate_fn:这是最关键的参数,它指定了如何将 batch_size 个单独的样本“校对”和“打包”成一个规整的批次。传入的 collate_batch 函数在这里完成了动态填充和 attention_mask 的创建工作。
为什么 tag_ids 的填充值是 -100?
这是一个 PyTorch 中的惯例。在计算损失时,我们不希望填充位置的标签对最终的损失值和梯度产生影响。PyTorch 的交叉熵损失函数 torch.nn.CrossEntropyLoss 中有一个参数 ignore_index,它的默认值恰好是 -100。
当损失函数看到标签值为 -100 时,会自动“忽略”这个位置,不计算它的损失。
第三节 模型构建、训练与推理
书接上回,我们已经完成了 NER 项目的数据处理工作,包括构建标签映射、词汇表以及一个功能完备的 DataLoader。本节将聚焦于如何利用 PyTorch 构建一个序列标注模型,并进一步封装一个可复用的训练流程,最终实现模型的训练、评估与推理。
一、模型结构设计
正如第一节所介绍,NER 任务本质上是一个 序列标注 问题——为输入序列中的每一个 Token 预测一个对应的标签。基于此,可以设计一个有效的模型结构,它主要由三个核心部分组成:
- Token Embedding 层
- 作用:将输入的
token_ids(一串数字)转换为初始的词向量。 - 实现:通常使用
torch.nn.Embedding 层。它就像一个可学习的、巨大的查询表,每个 token_id 对应表中的一行(一个向量)。这些向量在训练开始时随机初始化,并随着模型训练过程不断优化。这个阶段产出的其实就是 静态词向量,因为它不考虑上下文,同一个字在任何句子中都对应同一个向量。
- 动态特征提取层
- 作用:让模型理解上下文,生成包含上下文特征信息的 动态词向量。由于静态词向量无法区分同一个词在不同上下文中的含义,所以需要一个 Encoder 来融合上下文信息,从而生成更能体现语义的动态词向量。
- 实现:循环神经网络 (RNN) 及其变体(如 LSTM, GRU)是处理序列数据的经典选择。我们可以使用 双向 GRU (Bi-GRU),它能够同时从左到右和从右到左两个方向捕捉序列信息,从而更全面地理解每个 Token 的上下文。当然,也可以使用其他更强大的模型,如 BERT,来作为特征提取器。
- 分类决策层
- 作用:基于包含上下文信息的动态词向量,为每个 Token 预测其最终的实体标签(如
B-dis, O 等)。 - 实现:通常使用一个简单的全连接层 (
torch.nn.Linear)。它将 Encoder 输出的动态词向量从 hidden_size 维度映射到 num_classes(标签总数)维度,得到的输出即为每个 Token 在所有标签上的置信度得分。
整个模型本质上是一个 Token 分类模型:接收 Token 序列,并为其中的每一个 Token 输出一个分类结果。
二、构建 PyTorch 模型
编写模型代码之前,先来回顾一下 DataLoader 输出的数据。如下图所示,经过 collate_fn 处理后,每个批次(Batch)的数据都包含了三个 torch.Tensor:token_ids、label_ids 和 attention_mask。
其中,token_ids 是模型最直接的输入,它是一个 torch.int64 类型的张量,代表了文本序列转换后的 Token 索引。
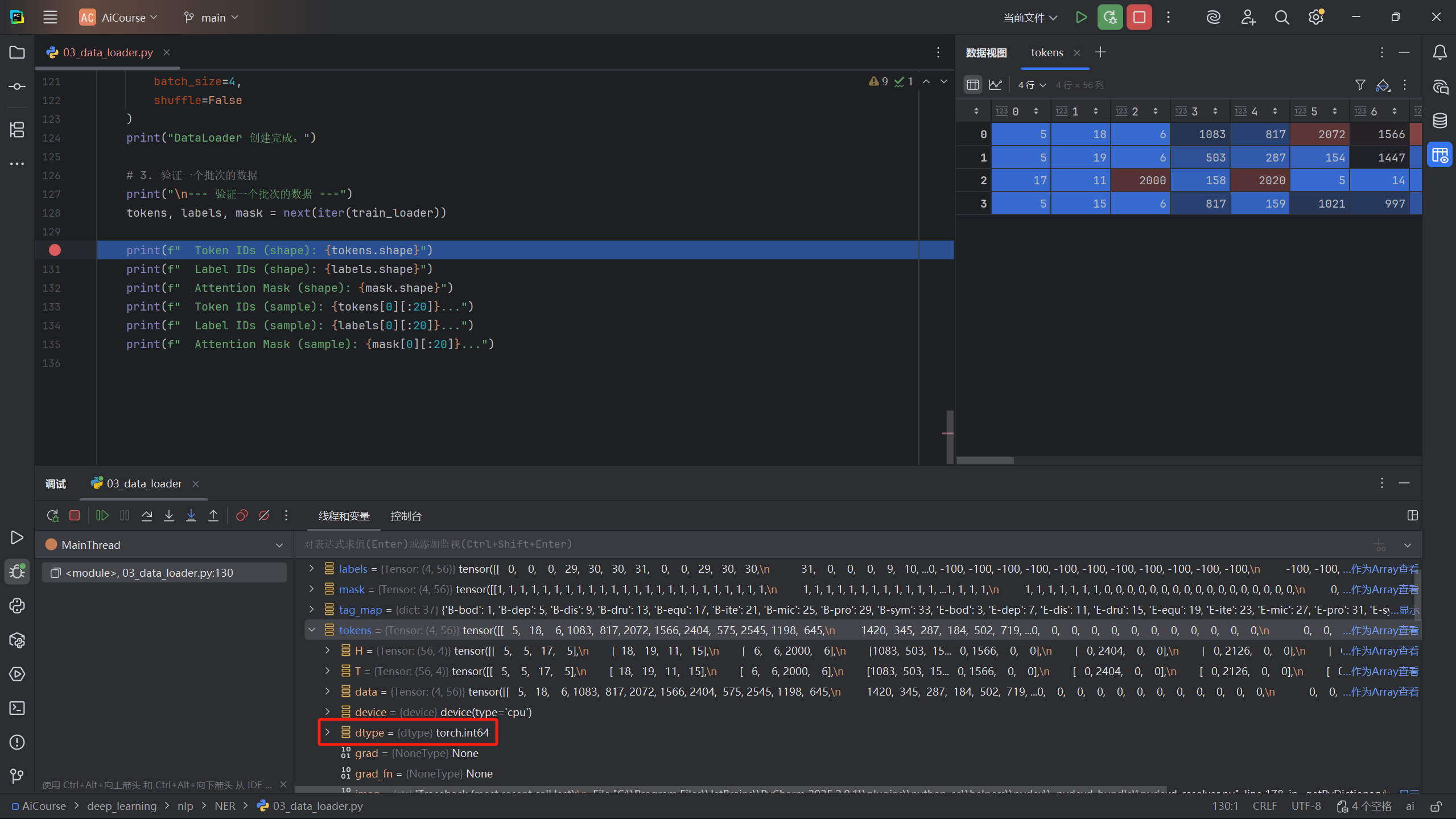
图 3.1: 数据加载器输出示例
2.1 输入与输出
为了在代码层面更清晰地展示这些张量,我们直接复制如图 3.1 所示的真实数据片段。这有助于在正式实现模型前,先通过这组数据核对输入/输出的维度与取值约定(例如 -100 表示忽略位置)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| import torch
if __name__ == '__main__':
token_ids = torch.tensor([
[210, 18, 871, 147, 0, 0, 0, 0],
[922, 2962, 842, 210, 18, 871, 147, 0]
], dtype=torch.int64)
# attention_mask 标记哪些是真实 token (1) 哪些是填充 (0)
attention_mask = torch.tensor([
[1, 1, 1, 1, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 0]
], dtype=torch.int64)
label_ids = torch.tensor([
[0, 0, 0, 0, -100, -100, -100, -100],
[0, 0, 0, 0, 0, 0, 0, -100]
], dtype=torch.int64)
|
从上面的示例中可以知道:
- 输入:模型需要接收两个参数,
token_ids 和 attention_mask。 - 输出:模型的输出
logits 是一个三维张量,形状为 [batch_size, seq_len, num_tags]。
2.2 基础模型框架
目标明确后,就可以开始搭建模型了。先从一个最基础的单向 GRU 模型 GRUNerNetWork 开始。它包含 __init__ 构造函数和 forward
前向传播方法。为了构建一个更强大、更灵活的深度模型,这里采用 nn.ModuleList 来显式地堆叠多个 GRU 层。这种做法不仅让网络结构更清晰,还允许我们在层与层之间轻松地加入残差连接,这对于训练深度网络很重要。
nn.ModuleList vs nn.Sequential
在 PyTorch 中,nn.ModuleList 和 nn.Sequential 都是用来容纳多个子模块的容器,但它们的设计思想和使用场景不同:
nn.Sequential:像一个自动化的流水线,数据会自动按顺序流过每一层。适用于简单的线性堆叠,但无法实现层间的复杂交互。nn.ModuleList:更像一个普通的 Python 列表,只负责存储模块,而不会自动执行它们。你需要在 forward 方法中手动编写循环来调用每一层,所以可以在层与层之间加入自定义逻辑(如残差连接)。
对于这种情况,我们还需要做一个小的设计:将词向量的维度与 GRU 的隐状态维度 hidden_size 设置为相同的值,这样残差连接(即两个张量相加)才能顺利进行。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
| import torch.nn as nn
import torch.nn.utils.rnn as rnn
class GRUNerNetWork(nn.Module):
def __init__(self, vocab_size, hidden_size, num_tags, num_gru_layers=1):
super().__init__()
# 1. Token Embedding 层
# 为了方便进行残差连接,embedding_dim 直接等于 hidden_size
self.embedding = nn.Embedding(vocab_size, hidden_size)
# 2. 使用 ModuleList 构建多层单向 GRU
self.gru_layers = nn.ModuleList()
for _ in range(num_gru_layers):
self.gru_layers.append(
nn.GRU(
input_size=hidden_size, # 输入维度统一为 hidden_size
hidden_size=hidden_size,
num_layers=1,
batch_first=True,
bidirectional=False
)
)
# 3. 分类决策层
self.classifier = nn.Linear(hidden_size, num_tags)
def forward(self, token_ids, attention_mask=None):
# [batch_size, seq_len] -> [batch_size, seq_len, hidden_size]
embedded_text = self.embedding(token_ids)
current_input = embedded_text
for gru_layer in self.gru_layers:
gru_output, _ = gru_layer(current_input)
# 添加残差连接
current_input = gru_output + current_input
logits = self.classifier(current_input)
return logits
if __name__ == '__main__':
# ... (数据构建) ...
# 实例化模型
model = GRUNerNetWork(
vocab_size=10000,
hidden_size=128,
num_tags=37,
num_gru_layers=2
)
# 3. 执行前向传播
logits = model(token_ids=token_ids)
# 4. 构造损失函数
loss_fn = nn.CrossEntropyLoss(ignore_index=-100, reduction='none')
# 5. 计算损失
# CrossEntropyLoss 要求类别维度在前,所以需要交换最后两个维度
# [batch, seq_len, num_tags] -> [batch, num_tags, seq_len]
permuted_logits = torch.permute(logits, dims=(0, 2, 1))
loss = loss_fn(permuted_logits, label_ids)
# 6. 打印结果
print(f"Logits shape: {logits.shape}")
print(f"Loss shape: {loss.shape}")
print("\n每个 Token 的损失:")
print(loss)
|
运行结果:
1
2
3
4
5
6
7
| Logits shape: torch.Size([2, 8, 10])
Loss shape: torch.Size([2, 8])
每个 Token 的损失:
tensor([[2.3364, 2.2961, 2.3879, 2.3275, 0.0000, 0.0000, 0.0000, 0.0000],
[2.2855, 2.3020, 2.2478, 2.3787, 2.2882, 2.3392, 2.3553, 0.0000]],
grad_fn=<ViewBackward0>)
|
这段输出说明:
- 维度正确:模型的输出
logits 维度为 [2, 8, 10],与 [batch_size, seq_len, num_tags] 对应。 - 损失形状正确:由于设置了
reduction='none',损失张量的形状 [2, 8] 与 label_ids 一致,返回了每个 Token 各自的损失。 ignore_index 生效:可以看到 label_ids 中值为 -100 的填充位置,其对应的损失值为 0。这证明损失函数成功忽略了这些填充位,避免了无效信息对模型训练的干扰。
你可能会注意到,在 GRUNerNetWork 的 forward 方法中,并没有使用 attention_mask 来处理填充。那为什么模型还能正常工作?
这是 单向 GRU 的计算特性 和 损失函数的 ignore_index 机制 共同作用的结果:
- 单向计算:GRU 从左到右处理序列,在计算一个真实 Token(如
w_i)的特征时,它只依赖于其左侧的上下文(w_1, ..., w_{i-1})。序列末尾的 Padding Token 不会影响 到它前面真实 Token 的特征计算。 - 损失忽略:Padding Token 虽然也会经过模型产生
logits,但由于在 label_ids 中已将这些位置标记为 -100,损失函数会自动忽略这些位置的损失。
所以,对于单向 RNN,Padding 虽然参与了计算,但其产生的影响最终被损失函数“屏蔽”了。不过,这种“侥幸”在双向模型中将不复存在。
2.3 双向模型改进
单向 GRU 的局限性导致其无法看到未来的上下文。在当前的任务中为了让模型在预测每一个 Token 时都能同时“左顾右盼”,最简单的改进就是引入 双向 GRU。不过,我们 不能通过简单地设置 bidirectional=True 来实现双向 GRU。
因为,双向 GRU 包含一个从右到左的反向传播路径。它会从序列的末尾开始计算,如果末尾都是无意义的 <PAD> 标记,那么这些“垃圾信息”就会作为初始状态,一路污染到序列中真实的 Token 表示中去。所以,需要一种方法来“告知”GRU 每个序列的真实长度,让它在计算时能够忽略掉这些填充位。
2.3.1 变长序列处理
既然问题的源于 RNN 无法区分真实 Token 和填充位,那么解决方案的重点就是:在将数据送入 RNN 之前,以某种方式明确地告诉它每个序列的真实长度。
PyTorch 提供了一套工具——torch.nn.utils.rnn.pack_padded_sequence。可以先来看看它的源码定义,重点关注输入参数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| # torch/nn/utils/rnn.py
def pack_padded_sequence(
input: Tensor,
lengths: Union[Tensor, list[int]],
batch_first: bool = False,
enforce_sorted: bool = True,
) -> PackedSequence:
r"""Packs a Tensor containing padded sequences of variable length.
# ... (省略大部分文档) ...
Args:
input (Tensor): 经过填充的、变长的序列批次。
lengths (Tensor or list(int)): 一个列表或张量,包含了批次中每个序列的真实长度。
batch_first (bool, optional): 如果为 True,则输入张量的形状为 (B, T, *)。
enforce_sorted (bool, optional): 如果为 True (默认),则要求输入序列已按长度降序排列。
如果为 False,函数会在内部自动进行排序。
Returns:
一个 PackedSequence 对象
"""
# ... (省略内部实现逻辑) ...
|
从源码中可以看到,这个函数的主要作用是接收一个 填充后 的 input 张量,以及一个记录了 真实长度 的 lengths 列表。它会返回一个 PackedSequence 对象,可以把它想象成一个“压缩”后的数据包,其中所有的填充位都被暂时移除了。RNN 模块在接收到这个特殊对象后,其内部就能正确、高效地处理变长序列。
当然,有“打包”就有“解包”。与之对应的 pad_packed_sequence 函数会负责将 RNN 计算完成后的 PackedSequence 对象再“解压”还原成带有填充的、规整的 Tensor。
2.3.2 BiGRUNerNetWork 代码实现
理解了“打包-解包”机制后,就可以动手改造 GRUNerNetWork 了。代码的主要改动如下:
- 开启双向:在
nn.GRU 的参数中设置 bidirectional=True。 - 增加特征融合层:由于双向 GRU 的输出维度会变为
hidden_size * 2,需要增加一个全连接层,将拼接后的特征重新映射回 hidden_size,以便与输入进行残差连接。 - 集成 Pack/Pad:在
forward 方法中,实现完整的“计算长度 -> 打包 -> GRU 计算 -> 解包 -> 残差连接”流程。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
| class BiGRUNerNetWork(nn.Module):
def __init__(self, vocab_size, hidden_size, num_tags, num_gru_layers=1):
super().__init__()
# 1. Token Embedding 层
self.embedding = nn.Embedding(vocab_size, hidden_size)
# 2. 使用 ModuleList 构建多层双向 GRU
self.gru_layers = nn.ModuleList()
for _ in range(num_gru_layers):
self.gru_layers.append(
nn.GRU(
input_size=hidden_size,
hidden_size=hidden_size,
num_layers=1,
batch_first=True,
bidirectional=True # 开启双向
)
)
# 3. 特征融合层
self.fc = nn.Linear(hidden_size * 2, hidden_size)
# 4. 分类决策层 (Classifier)
self.classifier = nn.Linear(hidden_size, num_tags)
def forward(self, token_ids, attention_mask):
# 1. 计算真实长度
lengths = attention_mask.sum(dim=1).cpu()
# 2. 获取词向量
embedded_text = self.embedding(token_ids)
# 3. 打包序列
current_packed_input = rnn.pack_padded_sequence(
embedded_text, lengths, batch_first=True, enforce_sorted=False
)
# 4. 循环通过 GRU 层
for gru_layer in self.gru_layers:
# GRU 输出 (packed)
packed_output, _ = gru_layer(current_packed_input)
# 解包以进行后续操作,并指定 total_length
output, _ = rnn.pad_packed_sequence(
packed_output, batch_first=True, total_length=token_ids.shape[1]
)
# 特征融合
features = self.fc(output)
# 残差连接
# 同样需要解包上一层的输入
input_padded, _ = rnn.pad_packed_sequence(
current_packed_input, batch_first=True, total_length=token_ids.shape[1]
)
current_input = features + input_padded
# 重新打包作为下一层的输入
current_packed_input = rnn.pack_padded_sequence(
current_input, lengths, batch_first=True, enforce_sorted=False
)
# 5. 解包最终输出用于分类
final_output, _ = rnn.pad_packed_sequence(
current_packed_input, batch_first=True, total_length=token_ids.shape[1]
)
# 6. 分类
logits = self.classifier(final_output)
return logits
|
通过这番改造,BiGRUNerNetWork 才算是一个能够正确处理变长序列的、健壮的双向模型。
三、组件构建与训练封装
一个成熟的项目,其训练代码不应是零散的脚本,而应是结构化、可复用的框架。本节将从封装 Trainer 的训练与评估流程开始,逐步实现并接入模型、数据加载器、分词器、评估指标等组件,最后完成主程序的整体组装。
为了实现这一目标,我们采用的设计思路是 组件式组装 与 部门化分工:
Trainer 只负责“训练”: Trainer 类的核心职责是执行标准的训练和评估循环。它不关心模型是怎么构建的,也不关心数据是怎么加载的。- 组件由外部创建并“注入”: 模型、优化器、数据加载器等所有必要的组件都在外部被创建好,然后像零件一样被“注入”到
Trainer 的构造函数中。
3.1 搭建 Trainer 骨架
在开始编写 Trainer 类之前,先在 src/ 目录下创建一个 trainer 文件夹,并在其中新建一个 trainer.py 文件,用于存放 Trainer 类的定义。然后,定义 Trainer 类的基本结构。它通过构造函数接收所有必要的组件,并提供一个 fit 方法作为训练的统一入口。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
| # src/trainer/trainer.py
import torch
import os
class Trainer:
def __init__(self, model, optimizer, loss_fn, train_loader, dev_loader=None,
eval_metric_fn=None, output_dir=None, device='cpu'):
"""
初始化训练器。
Args:
model: PyTorch 模型。
optimizer: 优化器。
loss_fn: 损失函数。
train_loader: 训练数据加载器。
dev_loader: 验证数据加载器。
eval_metric_fn: 评估函数。
output_dir: 模型输出目录。
device: 训练设备。
"""
self.model = model.to(device)
self.optimizer = optimizer
self.loss_fn = loss_fn
self.train_loader = train_loader
self.dev_loader = dev_loader
self.eval_metric_fn = eval_metric_fn
self.output_dir = output_dir
self.device = torch.device(device)
if self.output_dir:
os.makedirs(self.output_dir, exist_ok=True)
def fit(self, epochs):
"""
训练的主入口,负责整个训练流程的调度。
"""
pass
def _train_one_epoch(self):
"""封装一个 epoch 的训练逻辑。"""
pass
def _train_step(self, batch):
"""封装一个训练步骤的逻辑(前向、损失、反向)。"""
pass
def _evaluate(self):
"""封装评估逻辑。"""
pass
def _evaluation_step(self, batch):
"""封装一个评估步骤的逻辑(前向、损失)。"""
pass
def _save_checkpoint(self, is_best=False):
"""封装模型保存逻辑。"""
pass
|
3.2 引入配置类管理参数
在搭建骨架时,会发现整个流程依赖于大量的参数,包括文件路径、模型超参数和训练设置。如果将这些参数零散地分布在代码中,会显得非常混乱且难以管理。
我们可以创建一个专门的 配置类 来统一管理所有这些参数。从最核心的几个参数开始定义:
- 路径参数:训练/验证集在哪,词汇表在哪,模型要输出到哪。
- 训练参数:
batch_size, epochs, learning_rate 等。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| # src/configs/configs.py
import torch
from dataclasses import dataclass, field
@dataclass
class NerConfig:
# --- 路径参数 ---
data_dir: str = "data"
train_file: str = "CMeEE-V2_train.json"
dev_file: str = "CMeEE-V2_dev.json"
vocab_file: str = "vocabulary.json"
tags_file: str = "categories.json"
output_dir: str = "output"
# --- 训练参数 ---
batch_size: int = 32
epochs: int = 20
learning_rate: float = 1e-3
device: str = field(default_factory=lambda: 'cuda' if torch.cuda.is_available() else 'cpu')
# --- 模型参数 ---
hidden_size: int = 256
num_gru_layers: int = 2
|
@dataclass 是 Python 3.7 引入的装饰器,可以简化类的编写。对于 TrainerConfig 这样的配置类,它会自动生成构造函数 (__init__),无需再手动编写冗长的参数赋值代码。同时,它还会生成一个友好的打印格式 (__repr__),这意味着 print(config) 会清晰地展示所有参数和值,便于调试。
3.3 完善 Trainer 类
有了 NerConfig,就可以回过头来完善 Trainer 的代码。在我们当前的“组件式组装”设计中,虽然 Trainer 不直接接收整个 config 对象(以保持解耦),但 config 依然是所有“零件”的参数来源。
接下来,填充 Trainer 类的完整实现,使其能够执行完整的训练和评估流程。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
| import torch
from tqdm import tqdm
import os
from dataclasses import asdict
class Trainer:
def __init__(self, model, optimizer, loss_fn, train_loader, dev_loader=None,
eval_metric_fn=None, output_dir=None, device='cpu'):
self.model = model.to(device)
self.optimizer = optimizer
self.loss_fn = loss_fn
self.train_loader = train_loader
self.dev_loader = dev_loader
self.eval_metric_fn = eval_metric_fn
self.output_dir = output_dir
self.device = torch.device(device)
if self.output_dir:
os.makedirs(self.output_dir, exist_ok=True)
def fit(self, epochs):
best_metric = float('inf') # 初始化一个无穷大的 best_metric,用于后续比较
for epoch in range(1, epochs + 1):
# 1. 执行一个周期的训练
train_loss = self._train_one_epoch()
print(f"Epoch {epoch} - Training Loss: {train_loss:.4f}")
# 2. 执行评估
metrics = self._evaluate()
if metrics:
print(f"Epoch {epoch} - Validation Metrics: {metrics}")
current_metric = metrics.get('loss') # 默认监控验证集 loss
# 3. 如果当前 metric 优于历史最优,则保存最佳模型
if current_metric < best_metric:
best_metric = current_metric
if self.output_dir:
self._save_checkpoint(is_best=True)
print(f"New best model saved with validation loss: {best_metric:.4f}")
# 4. 每个 epoch 结束后,保存最新的模型状态
if self.output_dir:
self._save_checkpoint(is_best=False)
def _train_one_epoch(self):
"""执行一个完整的训练周期。"""
self.model.train() # 设置为训练模式
total_loss = 0
# 使用 tqdm 显示进度条
for batch in tqdm(self.train_loader, desc=f"Training Epoch"):
outputs = self._train_step(batch)
total_loss += outputs['loss'].item() # 累加 loss
return total_loss / len(self.train_loader) # 返回平均 loss
def _train_step(self, batch):
"""执行单个训练步骤(前向、损失、反向)。"""
# 1. 将数据移动到指定设备
batch = {k: v.to(self.device) for k, v in batch.items() if isinstance(v, torch.Tensor)}
# 2. 模型前向传播
logits = self.model(token_ids=batch['token_ids'], attention_mask=batch['attention_mask'])
# 3. 计算损失
# CrossEntropyLoss 要求 logits 的形状为 [B, C, L],label_ids 的形状为 [B, L]
loss = self.loss_fn(logits.permute(0, 2, 1), batch['label_ids'])
# 4. 反向传播与参数更新
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
return {'loss': loss, 'logits': logits}
def _evaluate(self):
"""在验证集上执行评估。"""
if self.dev_loader is None:
return None
self.model.eval() # 设置为评估模式
total_loss = 0
all_logits = []
all_labels = []
all_attention_mask = []
with torch.no_grad(): # 禁用梯度计算
for batch in tqdm(self.dev_loader, desc="Evaluating"):
outputs = self._evaluation_step(batch)
total_loss += outputs['loss'].item()
# 收集所有批次的 logits 和 labels,用于后续评估
all_logits.append(outputs['logits'].cpu())
all_labels.append(batch['label_ids'].cpu())
all_attention_mask.append(batch['attention_mask'].cpu())
metrics = {}
# 如果提供了评估函数,则调用它来计算指标
if self.eval_metric_fn:
metrics = self.eval_metric_fn(all_logits, all_labels, all_attention_mask)
# 计算并记录平均 loss
metrics['loss'] = total_loss / len(self.dev_loader)
return metrics
def _evaluation_step(self, batch):
"""执行单个评估步骤(前向、损失)。"""
# 1. 将数据移动到指定设备
batch = {k: v.to(self.device) for k, v in batch.items() if isinstance(v, torch.Tensor)}
# 2. 模型前向传播
logits = self.model(token_ids=batch['token_ids'], attention_mask=batch['attention_mask'])
# 3. 计算损失
loss = self.loss_fn(logits.permute(0, 2, 1), batch['label_ids'])
return {'loss': loss, 'logits': logits}
def _save_checkpoint(self, is_best):
"""保存模型检查点。"""
state = {'model_state_dict': self.model.state_dict()}
if is_best:
# 保存最佳模型
torch.save(state, os.path.join(self.output_dir, 'best_model.pth'))
# 保存最新模型
torch.save(state, os.path.join(self.output_dir, 'last_model.pth'))
|
3.4 实现模型组件
完成通用的 Trainer 类之后,接下来就是一步步地去构建传入 __init__ 方法的各个组件。这里先来处理一下模型组件。
第一步:创建模型目录
在 src/ 目录下创建一个新的文件夹 models。
第二步:定义模型基类
在构建具体的模型之前,可以先在 src/models/ 目录下创建一个 base.py 文件来定义一个 模型基类。这个基类使用 Python 的 abc 模块(Abstract Base Classes)来规定所有 NER 模型都必须遵循的一个统一接口。
这样做的好处是:
- 强制接口统一:所有模型都必须实现一个
forward 方法,且接收相同的参数(token_ids, attention_mask)。这保证了 Trainer 可以与任何我们未来创建的新模型(如 BERT-NER, LSTM-NER)无缝协作,无需修改 Trainer 的代码。 - 提高可读性与可维护性:代码的结构更清晰,别人接手项目时,只需查看基类就能明白模型部分的接口规范。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| # src/models/base.py
import torch.nn as nn
from abc import ABC, abstractmethod
class BaseNerNetwork(nn.Module, ABC):
@abstractmethod
def forward(self, token_ids, attention_mask):
"""
定义所有 NER 模型都必须遵循的前向传播接口。
Args:
token_ids (torch.Tensor): [batch_size, seq_len]
attention_mask (torch.Tensor): [batch_size, seq_len]
Returns:
torch.Tensor: Logits, [batch_size, seq_len, num_tags]
"""
raise NotImplementedError
|
第三步:实现具体的 NER 模型
接下来,在 src/models 文件夹中创建一个新的 Python 文件,命名为 ner_model.py。可以将之前实现的 BiGRUNerNetWork 模型的代码直接复制到 ner_model.py 文件中,并让它 继承 我们刚刚定义的 BaseNerNetwork。
1
2
3
4
5
6
7
| # src/models/ner_model.py
import torch.nn as nn
import torch.nn.utils.rnn as rnn
from .base import BaseNerNetwork # 导入基类
class BiGRUNerNetWork(BaseNerNetwork): # 继承自 BaseNerNetwork
# ... (省略具体实现,与前文一致) ...
|
3.5 实现数据加载组件
在模型结构确定之后,需要为 Trainer 准备数据加载器(DataLoader)这个组件。通常分为两步:
- 创建
Dataset:负责读取单条数据,并将其转换为模型所需的张量(Tensor)。 - 创建
DataLoader:从 Dataset 中批量、随机地抓取数据,并通过 collate_fn 函数将它们整理成一个规整的批次(Batch)。
第一步:创建 NerDataset
在 src/data/ 目录下创建一个 dataset.py 文件,用于定义 NerDataset 类。同样的我们只需要复制之前在 03_data_loader.py 中实现过的 NerDataset 类就行。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
| # src/data/dataset.py
import torch
from torch.utils.data import Dataset
import json
class NerDataset(Dataset):
def __init__(self, data_path, tokenizer, tag_map):
self.tokenizer = tokenizer
self.tag_to_id = tag_map
# 直接加载和解析 JSON 文件
with open(data_path, 'r', encoding='utf-8') as f:
self.records = json.load(f)
def __len__(self):
return len(self.records)
def __getitem__(self, idx):
record = self.records[idx]
text = record['text']
tokens = self.tokenizer.text_to_tokens(text)
token_ids = self.tokenizer.tokens_to_ids(tokens)
tags = ['O'] * len(tokens)
for entity in record.get('entities', []):
entity_type = entity['type']
start = entity['start_idx']
end = entity['end_idx'] # 闭区间结束索引
if end >= len(tokens): continue
if start == end:
tags[start] = f'S-{entity_type}'
else:
tags[start] = f'B-{entity_type}'
tags[end] = f'E-{entity_type}'
for i in range(start + 1, end):
tags[i] = f'M-{entity_type}'
label_ids = [self.tag_to_id.get(tag, self.tag_to_id['O']) for tag in tags]
return {
"token_ids": torch.tensor(token_ids, dtype=torch.long),
"label_ids": torch.tensor(label_ids, dtype=torch.long)
}
|
第二步:重构代码,封装通用函数
在 NerDataset 中,使用 json.load 来读取数据。但是,在项目中,可能会在多个地方都需要读取 JSON 文件(比如加载词汇表、加载配置文件等)。为了避免代码重复,并让代码更具可维护性,可以将这个文件读取的逻辑封装成一个通用的函数。
在 src/ 目录下创建一个 utils 文件夹,并在其中新建一个 file_io.py 文件。我们将在这里存放所有与文件读写相关的工具函数。
1
2
3
4
5
6
7
8
9
10
11
12
| # src/utils/file_io.py
import json
def load_json(file_path):
"""从 JSON 文件加载数据。"""
with open(file_path, 'r', encoding='utf-8') as f:
return json.load(f)
def save_json(data, file_path):
"""将数据保存为 JSON 文件。"""
with open(file_path, 'w', encoding='utf-8') as f:
json.dump(data, f, ensure_ascii=False, indent=4)
|
然后回头优化 dataset.py 的代码,让它使用新创建的 load_json 函数。
1
2
3
4
5
6
7
8
9
10
11
12
| # src/data/dataset.py
import torch
from torch.utils.data import Dataset
from ..utils.file_io import load_json # 导入封装好的函数
class NerDataset(Dataset):
def __init__(self, data_path, tokenizer, tag_map):
self.tokenizer = tokenizer
self.tag_to_id = tag_map
self.records = load_json(data_path) # 调用通用函数,代码更简洁
# ... (省略 __len__ 和 __getitem__)
|
第三步:创建 DataLoader
在 src/data/ 目录下创建 data_loader.py 文件。复制 create_ner_dataloader 函数稍作调整来封装创建 DataLoader 的逻辑。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| # src/data/data_loader.py
from torch.utils.data import DataLoader
from torch.nn.utils.rnn import pad_sequence
from .dataset import NerDataset
def create_ner_dataloader(data_path, tokenizer, tag_map, batch_size, shuffle=False, device='cpu'):
dataset = NerDataset(data_path, tokenizer, tag_map)
def collate_batch(batch):
token_ids_list = [item['token_ids'] for item in batch]
label_ids_list = [item['label_ids'] for item in batch]
padded_token_ids = pad_sequence(token_ids_list, batch_first=True, padding_value=tokenizer.get_pad_id())
padded_label_ids = pad_sequence(label_ids_list, batch_first=True, padding_value=-100)
attention_mask = (padded_token_ids != tokenizer.get_pad_id()).long()
return {
"token_ids": padded_token_ids.to(device),
"label_ids": padded_label_ids.to(device),
"attention_mask": attention_mask.to(device)
}
return DataLoader(dataset, batch_size=batch_size, shuffle=shuffle, collate_fn=collate_batch)
|
3.6 实现分词器组件
至此,模型和数据加载器的结构都已就绪。但在 NerDataset 内部,还需要一个核心组件来处理原始文本:分词器。它的任务是将文本字符串,转换成模型能够理解的、由数字 ID 组成的序列。
第一步:定义分词器基类
与模型的设计类似,为分词器定义一个基类同样是一种推荐的做法,这能确保不同分词器实现之间接口的统一。在 src/tokenizer/ 目录下创建 base.py 文件。这保证了我们未来可能创建的任何新分词器(例如基于 Jieba 的分词器)都会遵循相同的接口规范,从而可以与 NerDataset 无缝对接。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| # src/tokenizer/base.py
from abc import ABC, abstractmethod
class BaseTokenizer(ABC):
@abstractmethod
def text_to_tokens(self, text: str) -> list[str]:
"""将文本分割成 token 列表。"""
raise NotImplementedError
@abstractmethod
def tokens_to_ids(self, tokens: list[str]) -> list[int]:
"""将 token 列表转换为 ID 列表。"""
raise NotImplementedError
def encode(self, text: str) -> list[int]:
"""将文本直接编码为 ID 列表的便捷方法。"""
tokens = self.text_to_tokens(text)
return self.tokens_to_ids(tokens)
@abstractmethod
def get_pad_id(self) -> int:
"""获取填充 token 的 ID。"""
raise NotImplementedError
|
第二步:实现字符级分词器
接下来,在 src/tokenizer/ 目录下创建 char_tokenizer.py。将分词和词汇表管理的所有逻辑都放在这一个类里。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| # src/tokenizer/char_tokenizer.py
from .base import BaseTokenizer
from ..utils.file_io import load_json
def normalize_text(text):
# ... (省略 normalize_text 函数实现) ...
class CharTokenizer(BaseTokenizer):
def __init__(self, vocab_path: str):
# 词汇表管理
self.tokens = load_json(vocab_path)
self.token_to_id = {token: i for i, token in enumerate(self.tokens)}
self.id_to_token = {i: token for i, token in enumerate(self.tokens)}
self.pad_id = self.token_to_id['<PAD>']
self.unk_id = self.token_to_id['<UNK>']
def __len__(self):
return len(self.tokens)
def text_to_tokens(self, text: str):
normalized_text = normalize_text(text)
return list(normalized_text)
def tokens_to_ids(self, tokens: list[str]):
return [self.token_to_id.get(token, self.unk_id) for token in tokens]
def get_pad_id(self) -> int:
return self.pad_id
|
第三步:创建词汇表管理器
为了让代码结构更清晰,可以将词汇表管理的功能抽离出来,封装成一个独立的 Vocabulary 类。在 src/tokenizer/ 目录下创建 vocabulary.py 文件,将之前 CharTokenizer 中 __init__ 方法里的词汇表逻辑迁移过来。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| # src/tokenizer/vocabulary.py
from ..utils.file_io import load_json
class Vocabulary:
"""
管理词汇表和 token 到 id 的映射。
"""
def __init__(self, vocab_path):
self.tokens = load_json(vocab_path)
self.token_to_id = {token: i for i, token in enumerate(self.tokens)}
self.id_to_token = {i: token for i, token in enumerate(self.tokens)}
self.pad_id = self.token_to_id['<PAD>']
self.unk_id = self.token_to_id['<UNK>']
def __len__(self):
return len(self.tokens)
def convert_tokens_to_ids(self, tokens):
return [self.token_to_id.get(token, self.unk_id) for token in tokens]
@classmethod
def load_from_file(cls, vocab_path):
return cls(vocab_path)
|
第四步:优化分词器
最后,我们回到 char_tokenizer.py,用新创建的 Vocabulary 类来重构它。可以看到,重构后的 CharTokenizer 将只负责分词。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| # src/tokenizer/char_tokenizer.py
from .vocabulary import Vocabulary
from .base import BaseTokenizer
def normalize_text(text):
# ... (省略 normalize_text 函数实现) ...
class CharTokenizer(BaseTokenizer):
def __init__(self, vocab: Vocabulary):
self.vocab = vocab
def text_to_tokens(self, text: str):
normalized_text = normalize_text(text)
return list(normalized_text)
def tokens_to_ids(self, tokens: list[str]):
return self.vocab.convert_tokens_to_ids(tokens)
def get_pad_id(self) -> int:
return self.vocab.pad_id
|
3.7 实现评估指标组件
对于 NER 任务,简单地计算每个 Token 的分类准确率是不够的。我们更关心的是模型作为一个整体,能否准确地、完整地抽取出命名实体。所以,需要计算实体级别(Entity-level)的指标:精确率(Precision)、召回率(Recall)和 F1 值。
计算这些指标的流程如下:
解码:将模型预测出的标签 ID 序列(如 [12, 13, 14, 0])转换回实体片段的列表(如 [('dis', 0, 3)])。
对比:将预测出的实体列表与真实的实体列表进行比较。
计算
:
- TP (True Positives):预测正确且与真实实体完全匹配(类型、起始和结束位置都相同)的实体数量。
- FP (False Positives):预测出的、但实际上不存在的实体数量。
- FN (False Negatives):真实存在、但模型未能预测出的实体数量。
- Precision = TP / (TP + FP)
- Recall = TP / (TP + FN)
- F1 = 2 (Precision Recall) / (Precision + Recall)
新建 src/metrics/ 目录并创建一个 entity_metrics.py 文件来实现这个逻辑。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
| # src/metrics/entity_metrics.py
import torch
def _trans_entity2tuple(label_ids, id2tag):
"""
将标签ID序列转换为实体元组列表(严格 BMES 解码)。
仅在遇到 E- 或 S- 时落盘;遇到新的 B- 或 O 不闭合未完成片段。
"""
entities = []
current_entity = None
for i, label_id in enumerate(label_ids):
# 将标签ID映射为字符串标签,未知则视作 'O'
tag = id2tag.get(label_id.item(), 'O')
if tag.startswith('B-'):
# 开启新片段:记录类型与起始位置;end 暂定为 i+1
current_entity = (tag[2:], i, i + 1)
elif tag.startswith('M-'):
# 仅当已存在片段,且类型一致时续接(扩展 end)
if current_entity and current_entity[0] == tag[2:]:
current_entity = (current_entity[0], current_entity[1], i + 1)
else:
# 类型不一致或不存在片段:丢弃未完成片段
current_entity = None
elif tag.startswith('E-'):
# 仅当已存在片段且类型一致时闭合并落盘
if current_entity and current_entity[0] == tag[2:]:
current_entity = (current_entity[0], current_entity[1], i + 1)
entities.append(current_entity)
# 无论是否匹配,E- 都视为一次片段结束
current_entity = None
elif tag.startswith('S-'):
# 单字实体:直接落盘(start=i, end=i+1)
entities.append((tag[2:], i, i + 1))
current_entity = None
else: # 'O'
# 非实体位置:严格模式不闭合未完成片段,直接丢弃
current_entity = None
# 返回集合去重
return set(entities)
def calculate_entity_level_metrics(all_pred_ids, all_label_ids, id2tag):
"""
逐样本评估(未使用 mask),解码采用严格 BMES。
"""
true_entities = set()
pred_entities = set()
# 遍历批次中的每一个样本
for i in range(len(all_label_ids)):
# 将标签ID序列解码为实体集合(严格 BMES)
sample_true_entities = _trans_entity2tuple(all_label_ids[i], id2tag)
sample_pred_entities = _trans_entity2tuple(all_pred_ids[i], id2tag)
true_entities.update(sample_true_entities)
pred_entities.update(sample_pred_entities)
# 计算 TP / FP / FN
num_correct = len(true_entities.intersection(pred_entities)) # TP
num_true = len(true_entities) # TP + FN
num_pred = len(pred_entities) # TP + FP
# 计算 P / R / F1(含零保护)
precision = num_correct / num_pred if num_pred > 0 else 0.0
recall = num_correct / num_true if num_true > 0 else 0.0
f1 = 2 * (precision * recall) / (precision + recall) if (precision + recall) > 0 else 0.0
return {"precision": precision, "recall": recall, "f1": f1}
|
批量评估中的挑战与解决方案:
当前 calculate_entity_level_metrics 的实现,在面对 Trainer 的批量评估场景时,会遇到两个问题:
- 处理填充:在一个批次中,不同长度的句子会被填充到相同长度。这些填充位(Padding)不应参与评估。我们需要利用
attention_mask 机制,来过滤掉所有因填充而产生的无效 Token,确保评估只在有效的序列片段上进行。 - 追踪样本来源:当处理一个批次的多个样本时,必须能区分每个实体到底来自哪个样本。例如,批次中的第一个样本和第二个样本可能在相同的位置
(0, 2) 都有一个 'dis' 类型的实体。如果在解码时不加以区分,这两个独立的实体在存入 set 时会被误判为同一个。为了准确区分来自同一批次中不同样本的实体,设计了一种方案:为每个解码出的实体附加其所在样本的唯一ID(即批次内索引 i)。确保每个实体都由一个唯一的 (样本ID, 实体类型, 起始位置, 结束位置) 四元组来标识,从根本上解决实体归属混淆的问题。
改进后的 calculate_entity_level_metrics 函数实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
| # src/metrics/entity_metrics.py
# _trans_entity2tuple 函数同上,此处省略...
def calculate_entity_level_metrics(all_pred_ids, all_label_ids, all_masks, id2tag):
"""
计算实体级别的精确率、召回率和 F1 分数。
"""
true_entities = set()
pred_entities = set()
sample_idx = 0
# 按批次遍历,同时保持 preds/labels/masks 对齐
for preds_batch, labels_batch, masks_batch in zip(all_pred_ids, all_label_ids, all_masks):
B = labels_batch.shape[0] # 当前批次样本数
for b in range(B):
# 对单个样本应用布尔掩码,去除 padding 位置
row_mask = masks_batch[b].bool()
row_labels = labels_batch[b][row_mask]
row_preds = preds_batch[b][row_mask]
# 严格 BMES 解码为实体集合
te = _trans_entity2tuple(row_labels, id2tag)
pe = _trans_entity2tuple(row_preds, id2tag)
# 为每个实体附加 (sample_idx,) 前缀,确保不同样本的相同实体不冲突
true_entities.update({(sample_idx,) + e for e in te})
pred_entities.update({(sample_idx,) + e for e in pe})
sample_idx += 1
num_correct = len(true_entities.intersection(pred_entities))
num_true = len(true_entities)
num_pred = len(pred_entities)
precision = num_correct / num_pred if num_pred > 0 else 0.0
recall = num_correct / num_true if num_true > 0 else 0.0
f1 = 2 * (precision * recall) / (precision + recall) if (precision + recall) > 0 else 0.0
return {"precision": precision, "recall": recall, "f1": f1}
|
3.8 组装所有组件
最后让我们组装刚才实现的各个组件。在根目录创建一个 05_train.py 文件,它将导入并组装在 src/ 目录下构建的所有模块。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
| # 05_train.py
import os
import torch
import torch.nn as nn
# 导入定义的所有组件
from src.configs.configs import config
from src.data.data_loader import create_ner_dataloader
from src.tokenizer.vocabulary import Vocabulary
from src.tokenizer.char_tokenizer import CharTokenizer
from src.models.ner_model import BiGRUNerNetWork
from src.trainer.trainer import Trainer
from src.utils.file_io import load_json
from src.metrics.entity_metrics import calculate_entity_level_metrics
def main():
"""
主函数,负责组装所有组件并启动NER训练任务。
"""
# --- 1. 加载词汇表和标签映射, 并创建分词器 ---
vocab_path = os.path.join(config.data_dir, config.vocab_file)
tags_path = os.path.join(config.data_dir, config.tags_file)
train_path = os.path.join(config.data_dir, config.train_file)
dev_path = os.path.join(config.data_dir, config.dev_file)
vocab = Vocabulary.load_from_file(vocab_path)
tokenizer = CharTokenizer(vocab)
tag_map = load_json(tags_path)
id2tag = {v: k for k, v in tag_map.items()}
# --- 2. 创建数据加载器 ---
train_loader = create_ner_dataloader(
data_path=train_path,
tokenizer=tokenizer,
tag_map=tag_map,
batch_size=config.batch_size,
shuffle=True,
device=config.device
)
dev_loader = create_ner_dataloader(
data_path=dev_path,
tokenizer=tokenizer,
tag_map=tag_map,
batch_size=config.batch_size,
shuffle=False,
device=config.device
)
# --- 3. 初始化模型、优化器、损失函数 ---
model = BiGRUNerNetWork(
vocab_size=len(vocab),
hidden_size=config.hidden_size,
num_tags=len(tag_map),
num_gru_layers=config.num_gru_layers
)
optimizer = torch.optim.AdamW(model.parameters(), lr=config.learning_rate)
loss_fn = nn.CrossEntropyLoss(ignore_index=-100)
# --- 4. 定义评估函数 ---
def eval_metric_fn(all_logits, all_labels, all_attention_mask):
# 将模型输出的 logits 转换为预测的 tag id
all_preds_ids = [torch.argmax(logits, dim=-1) for logits in all_logits]
# 将所有数据移动到 CPU 以便进行后续计算
all_labels_cpu = [labels.cpu() for labels in all_labels]
all_preds_ids_cpu = [preds.cpu() for preds in all_preds_ids]
all_attention_mask_cpu = [mask.cpu() for mask in all_attention_mask]
# 将 attention_mask 转换为布尔类型,用于过滤 padding
active_masks = [mask.bool() for mask in all_attention_mask_cpu]
# 基于 mask 的 token 级准确率
total_equal_tokens, total_effective_tokens = 0, 0
for preds, labels, mask in zip(all_preds_ids_cpu, all_labels_cpu, active_masks):
eq = (preds == labels) & mask
total_equal_tokens += int(eq.sum().item())
total_effective_tokens += int(mask.sum().item())
token_acc = (total_equal_tokens / total_effective_tokens) if total_effective_tokens > 0 else 0.0
# 调用之前定义的实体级评估函数
metrics = calculate_entity_level_metrics(
all_preds_ids_cpu,
all_labels_cpu,
active_masks,
id2tag
)
metrics['token_acc'] = token_acc
return metrics
# --- 5. 初始化并启动训练器 ---
trainer = Trainer(
model=model,
optimizer=optimizer,
loss_fn=loss_fn,
train_loader=train_loader,
dev_loader=dev_loader,
eval_metric_fn=eval_metric_fn,
output_dir=config.output_dir,
device=config.device
)
# 启动训练
trainer.fit(epochs=config.epochs)
if __name__ == "__main__":
main()
|
最终,我们完整地构建了从数据处理、模型构建、训练封装到评估的整个 NER 项目流程。在 code/C8/ 目录下,通过 python 05_train.py 命令,就可以启动整个训练过程。
第四节 模型的推理与优化
经过前面章节的数据处理、模型构建与训练,我们已经得到了一个可用的 NER 模型。本章将探讨如何实现模型的推理过程,并深入研究如何通过自定义损失函数来应对数据不均衡问题,通过集成可视化日志、提前停止和断点续训等功能,进一步提升训练框架的健壮性和实用性。
一、理解模型输出
在上一节构建 Trainer 时,已经明确了实体级别的 F1 值是衡量模型性能的核心标准,而非简单的 Token 分类准确率。这里探讨一下 为什么 需要这样做,以及这对设计推理流程有何启发。
1.1 Token 级准确率的陷阱
最直接的评估方式是计算 Token 级别的分类准确率,即模型预测正确的标签数占总标签数的比例。不过,正如在上一节中讨论过的,这个指标具有误导性,尤其是在实体词占比较低的场景中。主要问题在于 数据不均衡。在大部分文本中,绝大多数的 Token 标签都是 'O'(非实体)。一个“聪明”但完全没用的模型,如果它将所有 Token 都预测为 'O',也能轻松达到一个非常高的 Token 准确率。但是,这样的模型没有识别出任何一个实体,对于当前的任务来说毫无价值。
当模型训练到一定阶段后,其预测结果可能会出现大量甚至全部为 'O'(ID 为 0)的情况。尽管此时的 Token 准确率看上去很高,但模型实际上已经陷入了通过预测多数类来最小化损失的“捷径”中,这是一种典型的过拟合现象,说明模型并没有真正学会识别实体。
1.2 对推理流程的启发
模型的原始输出(Token 标签序列)本身不是最终交付物。我们需要一个“后处理”或“解码”步骤,将这个标签序列转换成用户真正关心的结构化的实体列表。这不仅是正确评估模型的需要,也是模型能否在实际应用中创造价值的关键。
所以,当前的主要任务就是实现这个从标签序列到实体列表的解码过程。
二、从标签到实体:解码预测序列
模型的前向传播最终输出的是一个 logits 张量,形状为 [batch_size, seq_len, num_tags]。经过 argmax 操作后,会得到一个标签 ID 序列,例如 [0, 9, 10, 11, 0, ...]。
这个序列本身并不直观。为了进行实体级评估,或者将预测结果呈现给用户,必须实现一个 解码 (Decode) 函数,将这个数字序列转换成一个包含具体实体信息的列表,例如:[{"text": "高血压", "type": "dis", "start": 3, "end": 6}]。这个解码过程的核心,就是根据 BMES 标注体系的规则,从标签序列中解析出实体的边界和类型。
2.1 解码逻辑详解
解码函数需要遍历标签序列,并像一个“状态机”一样,根据当前遇到的标签(B, M, E, S, O)来维护一个 current_entity 对象。其解码逻辑如下:
- 遇到
B- (实体开始):- 如果此时还有一个未结束的
current_entity(说明上一个实体没有被 E- 正常闭合),则将其视为一个无效片段并放弃。 - 创建一个新的
current_entity 对象,记录下它的类型、起始位置和起始字符。
- 遇到
M- (实体中间):- 检查当前是否存在一个
current_entity,并且其类型与 M- 标签的类型是否一致。 - 如果一致,将当前字符追加到
current_entity 的 text 中。 - 如果不一致(例如
B-dis 后面跟了一个 M-sym),则说明这是一个非法的标签序列。我们将 current_entity 重置为 None,放弃这个不完整的片段。
- 遇到
E- (实体结束):- 与
M- 标签的检查逻辑类似,首先确保存在一个类型匹配的 current_entity。 - 如果匹配,将当前字符追加进去,并记录下结束位置
end = i + 1。 - 此时,一个完整的实体已经被识别出来,将其添加到最终的
entities 列表中。 - 最后,必须 将
current_entity 重置为 None,表示当前实体已处理完毕。
- 遇到
S- (单字实体):- 同样地,先放弃任何未闭合的
current_entity。 - 直接创建一个包含类型、文本、起始和结束位置的完整实体,并将其添加到
entities 列表中。
- 遇到
O (非实体):O 标签的出现意味着当前位置没有实体,或者一个实体刚刚结束。- 如果此时还有一个未闭合的
current_entity,放弃它,并将 current_entity 重置为 None。
这个过程确保了只有符合 BMES 规范、被正确“闭合”的实体才会被最终提取出来,继而保证了解码结果的健壮性。
解码策略:
当前采用的是一种 “严格”模式。任何不符合规范的序列(例如只有 B- 没有 E- 的实体)都会被直接放弃。这是最常见的做法,因为它能保证输出实体的规范性。
在某些特定的业务场景下,也可以采用更 “宽松”的策略。例如,如果模型预测出一个 B-M-O 的序列,可以选择将 B-M 这部分作为一个实体输出,而不是完全丢弃它。这种策略的选择,取决于具体应用对“召回率”和“精确率”的不同侧重,需要根据实际需求来决定。
2.2 代码实现
这个解码逻辑在 06_predict.py 中实现为一个名为 _extract_entities 的方法。它接收分词后的 tokens 列表和模型预测的 tags 列表作为输入,输出结构化的实体字典列表。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
| # code/C8/06_predict.py
def _extract_entities(self, tokens, tags):
entities = []
current_entity = None
for i, tag in enumerate(tags):
if tag.startswith('B-'):
# 如果前一个实体未正确结束,则放弃
if current_entity:
pass # 或者可以根据业务逻辑决定是否保存不完整的实体
current_entity = {"text": tokens[i], "type": tag[2:], "start": i}
elif tag.startswith('M-'):
# M 标签必须跟在 B- 或 M- 之后
if current_entity and current_entity["type"] == tag[2:]:
current_entity["text"] += tokens[i]
else:
# 非法 M 标签,重置当前实体
current_entity = None
elif tag.startswith('E-'):
# E 标签必须跟在 B- 或 M- 之后
if current_entity and current_entity["type"] == tag[2:]:
current_entity["text"] += tokens[i]
current_entity["end"] = i + 1
entities.append(current_entity)
# 实体已结束,重置
current_entity = None
elif tag.startswith('S-'):
# S 标签表示单个字符的实体
# 如果有未结束的实体,则放弃
current_entity = None
entities.append({"text": tokens[i], "type": tag[2:], "start": i, "end": i + 1})
else: # 'O' 标签
# O 标签意味着没有实体,或者实体已经结束
# 如果有未结束的实体,则放弃
current_entity = None
# 循环结束后,不再处理任何未闭合的实体
return entities
|
三、封装推理器
最后将所有推理相关的逻辑(加载模型、文本预处理、模型预测、结果解码)封装到一个 NerPredictor 类中,使其成为一个开箱即用的独立组件。
3.1 推理器的设计
一个好的推理器应该具备以下特点:
- 易于初始化: 只需提供训练好的模型目录,就能自动加载所有必要的资源(模型权重、配置文件、词汇表等)。
- 接口简洁: 提供一个简单的
predict(text) 方法,接收原始文本字符串,返回结构化的实体列表。 - 与训练解耦: 推理过程不应依赖任何训练时的代码或对象。
3.2 NerPredictor 核心流程
3.2.1 初始化 __init__
__init__ 方法的目标是加载并准备好所有推理所需的组件。
加载配置: 从模型目录加载 config.json,获取模型超参数和相关文件路径。
[开发插曲] 确保训练与推理的配置同步
在编写 NerPredictor 时,可能会遇到了一个问题:推理脚本需要知道训练时使用的模型配置(如 hidden_size 等)才能正确地重建模型,但之前的训练脚本 05_train.py 并没有将这些配置信息保存下来。
这会导致在运行 06_predict.py 时出现 FileNotFoundError: [Errno 2] No such file or directory: 'output/config.json' 的错误。
为了解决这个问题,回到 05_train.py,增加一步:在训练开始前,将当前的配置对象保存到输出目录中。这样,训练和推理阶段就能共享同一份配置,确保信息同步。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| # code/C8/05_train.py
from dataclasses import asdict
from src.utils.file_io import save_json
def main():
# ... (组件初始化)
trainer = Trainer(...)
# 在训练开始前,保存配置文件
os.makedirs(config.output_dir, exist_ok=True)
save_json(asdict(config), os.path.join(config.output_dir, "config.json"))
print(f"Configuration saved to {os.path.join(config.output_dir, 'config.json')}")
trainer.fit(epochs=config.epochs)
|
加载词汇表和标签映射: 根据配置文件中的路径,加载 vocabulary.json 和 tags.json,并构建 id2tag 映射。
加载分词器: 初始化 CharTokenizer。
初始化模型并加载权重:
- 根据配置实例化
BiGRUNerNetWork 模型。 - 从模型目录加载
best_model.pth 模型权重。这里需要使用 map_location=self.device 来确保模型可以被加载到指定的设备上(无论是 CPU 还是 GPU)。 - 调用
model.to(self.device) 将模型移至指定设备。 - 调用
model.eval() 将模型切换到评估模式,关闭 Dropout 和 BatchNorm 等只在训练时使用的层,确保预测结果的确定性。
3.2.2 预测 predict
predict 方法负责执行从原始文本到实体列表的完整端到端流程。
预处理
:
- 调用
tokenizer 将输入文本转换为 token_ids。 - 将
token_ids 转换为 torch.Tensor,并添加一个 batch 维度(因为模型期望的输入是 [batch_size, seq_len])。 - 创建
attention_mask。 - 将所有张量移动到
self.device。
模型预测
:
- 使用
with torch.no_grad(): 临时禁用梯度计算,减少内存消耗并加速推理过程。 - 将
token_ids 和 attention_mask 送入模型,得到 logits。
后处理
:
- 对
logits 在最后一个维度上执行 argmax,得到预测的 label_ids 序列。 - 使用
id2tag 映射,将 label_ids 转换为 tags 字符串列表。 - 调用
_extract_entities 方法,完成最终的解码,返回实体列表。
3.3 完整代码实现
在清晰地理解了设计思路和流程后,下面是 06_predict.py 的完整代码。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
| # code/C8/06_predict.py
import torch
import json
import os
import argparse
from src.models.ner_model import BiGRUNerNetWork
from src.tokenizer.vocabulary import Vocabulary
from src.tokenizer.char_tokenizer import CharTokenizer
from src.utils.file_io import load_json
class NerPredictor:
def __init__(self, model_dir, device='cpu'):
self.device = torch.device(device)
# --- 1. 加载配置文件以获取模型参数 ---
config_path = os.path.join(model_dir, 'config.json')
self.config = load_json(config_path)
# --- 2. 加载词汇表和标签映射 ---
vocab_path = os.path.join(self.config["data_dir"], self.config["vocab_file"])
tags_path = os.path.join(self.config["data_dir"], self.config["tags_file"])
self.vocab = Vocabulary.load_from_file(vocab_path)
self.tokenizer = CharTokenizer(self.vocab)
tag_map = load_json(tags_path)
self.id2tag = {v: k for k, v in tag_map.items()}
# --- 3. 初始化模型并加载权重 ---
self.model = BiGRUNerNetWork(
vocab_size=len(self.vocab),
hidden_size=self.config["hidden_size"],
num_tags=len(tag_map),
num_gru_layers=self.config["num_gru_layers"]
)
model_path = os.path.join(model_dir, 'best_model.pth')
self.model.load_state_dict(torch.load(model_path, map_location=self.device)['model_state_dict'])
self.model.to(self.device)
self.model.eval()
def predict(self, text):
tokens = self.tokenizer.text_to_tokens(text)
token_ids = self.tokenizer.tokens_to_ids(tokens)
# --- 预处理 ---
token_ids_tensor = torch.tensor([token_ids], dtype=torch.long).to(self.device)
attention_mask = torch.ones_like(token_ids_tensor)
# --- 模型预测 ---
with torch.no_grad():
logits = self.model(token_ids_tensor, attention_mask)
# --- 后处理 ---
predictions = torch.argmax(logits, dim=-1).squeeze(0)
tags = [self.id2tag[id_.item()] for id_ in predictions]
return self._extract_entities(tokens, tags)
def _extract_entities(self, tokens, tags):
entities = []
current_entity = None
for i, tag in enumerate(tags):
if tag.startswith('B-'):
if current_entity:
pass
current_entity = {"text": tokens[i], "type": tag[2:], "start": i}
elif tag.startswith('M-'):
if current_entity and current_entity["type"] == tag[2:]:
current_entity["text"] += tokens[i]
else:
current_entity = None
elif tag.startswith('E-'):
if current_entity and current_entity["type"] == tag[2:]:
current_entity["text"] += tokens[i]
current_entity["end"] = i + 1
entities.append(current_entity)
current_entity = None
elif tag.startswith('S-'):
current_entity = None
entities.append({"text": tokens[i], "type": tag[2:], "start": i, "end": i + 1})
else: # 'O' 标签
current_entity = None
return entities
def main():
parser = argparse.ArgumentParser(description="NER Prediction")
parser.add_argument("--model_dir", type=str, required=True, help="Directory of the saved model and config.")
parser.add_argument("--text", type=str, required=True, help="Text to predict.")
args = parser.parse_args()
predictor = NerPredictor(model_dir=args.model_dir)
entities = predictor.predict(args.text)
print(f"Text: {args.text}")
print(f"Entities: {json.dumps(entities, ensure_ascii=False, indent=2)}")
if __name__ == "__main__":
main()
|
3.4 使用示例
06_predict.py 的 main 函数提供了一个标准的命令行使用接口。在训练完成后,可以通过以下命令来调用训练好的模型进行预测:
1
| python 06_predict.py --model_dir "output" --text "患者自述发热、咳嗽,伴有轻微头痛。"
|
--model_dir: 指向我们第三节中训练结果的输出目录(包含了 best_model.pth 和 config.json)。--text: 需要进行实体识别的文本。
预期输出:
由于我们仅进行了简单的训练,并未进行调优,所以当前模型的预测结果可能并不完美(例如可能只识别出部分实体或单字实体)。这里展示的输出主要是为了说明整个推理流程的格式和工作方式。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| Text: 患者自述发热、咳嗽,伴有轻微头痛。
Entities: [
{
"text": "发",
"type": "sym",
"start": 4,
"end": 5
},
{
"text": "咳",
"type": "sym",
"start": 7,
"end": 8
}
]
|
四、自定义损失函数
在当前使用的 CMeEE 数据集中,数据不均衡是一个显著的特点:大部分 Token 都是非实体的 ‘O’ 标签。虽然导致模型性能不佳的原因可能多种多样,但这种数据不均衡无疑是影响模型学习效果的关键因素之一。仅仅依赖实体级评估指标是在“下游”进行补救,我们也可以尝试从“上游”——即损失函数的设计入手,主动引导模型去关注实体样本。
标准的交叉熵损失函数对所有 Token 一视同仁,当 'O' 标签占据绝大多数时,损失值自然会被这些“多数派”主导。下面介绍两种策略,来尝试缓解这个问题。
4.1 核心策略
4.1.1 加权交叉熵损失
最简单的方法就是“加权”。给数量稀少的实体标签(B, M, E, S)一个更高的权重,给数量庞大的非实体标签(O)一个较低的权重。例如,我们可以设置实体损失的权重为 10,非实体损失的权重为 1。这样,模型在反向传播时,如果弄错了一个实体 Token,会受到比弄错一个非实体 Token 大 10 倍的“惩罚”,从而迫使模型更加关注对实体的识别。
4.1.2 硬负样本挖掘
另一种思路是“采样”。在大量的非实体样本中,大部分是模型可以轻易正确预测的“简单样本”,它们对损失的贡献很小,反复学习意义不大。真正有价值的是那些模型容易搞错的“硬负样本”,例如一个模型倾向于预测为实体的非实体 Token。
硬负样本挖掘的做法是:在计算非实体部分的损失时,不计算所有非实体 Token 的平均损失,而是只选择其中损失值最大(Top-K)的一部分进行计算和反向传播。这样就相当于从海量的“多数派”中,筛选出了最有价值的“疑难样本”进行学习,提升了训练的效率和效果。
4.2 代码实现
为了将上述策略集成到训练框架中,来创建一个新的 NerLoss 类,并修改项目的相关部分来调用它。
4.2.1 创建 NerLoss
首先,在 src 目录下创建一个新的 loss 文件夹,并在其中新建 ner_loss.py 文件。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
| # code/C8/src/loss/ner_loss.py
import torch
import torch.nn as nn
class NerLoss(nn.Module):
"""
自定义 NER 损失函数,集成两种策略来对抗数据不均衡问题:
1. 加权交叉熵
2. 硬负样本挖掘
"""
def __init__(self, loss_type='cross_entropy', entity_weight=10.0, hard_negative_ratio=0.5, ignore_index=-100):
super().__init__()
# --- 参数定义 ---
self.loss_type = loss_type # 损失类型: 'cross_entropy', 'weighted_ce', 'hard_negative_mining'
self.entity_weight = entity_weight # 实体损失的权重
self.hard_negative_ratio = hard_negative_ratio # 硬负样本与正样本的比例
# 基础损失函数,设置为 'none' 模式以获取每个 token 的单独损失
self.base_loss_fn = nn.CrossEntropyLoss(reduction='none', ignore_index=ignore_index)
def forward(self, logits, labels):
"""
根据初始化时选择的 loss_type 计算损失。
"""
if self.loss_type == 'weighted_ce':
return self._weighted_cross_entropy(logits, labels)
elif self.loss_type == 'hard_negative_mining':
return self._hard_negative_mining(logits, labels)
else:
# 默认使用 PyTorch 原生的交叉熵损失
return self.base_loss_fn(logits, labels).mean()
def _weighted_cross_entropy(self, logits, labels):
"""
加权交叉熵损失的实现。
"""
# 计算每个 token 的基础损失, shape: [batch_size, seq_len]
loss_per_token = self.base_loss_fn(logits, labels)
# 创建掩码来区分实体和非实体 token
entity_mask = (labels > 0).float() # 实体 (B, M, E, S)
non_entity_mask = (labels == 0).float() # 非实体 (O)
# 分别计算实体和非实体部分的平均损失
entity_loss = torch.sum(loss_per_token * entity_mask) / (torch.sum(entity_mask) + 1e-8)
non_entity_loss = torch.sum(loss_per_token * non_entity_mask) / (torch.sum(non_entity_mask) + 1e-8)
# 根据预设权重,组合两部分损失
total_loss = self.entity_weight * entity_loss + 1.0 * non_entity_loss
return total_loss, entity_loss.detach(), non_entity_loss.detach()
def _hard_negative_mining(self, logits, labels):
"""
硬负样本挖掘损失的实现。
"""
# 计算每个 token 的基础损失
loss_per_token = self.base_loss_fn(logits, labels)
# 实体部分的损失计算与加权交叉熵方法相同
entity_mask = (labels > 0).float()
entity_loss = torch.sum(loss_per_token * entity_mask) / (torch.sum(entity_mask) + 1e-8)
# 筛选出所有非实体 token 的损失
non_entity_mask = (labels == 0).float()
non_entity_loss = loss_per_token * non_entity_mask
# 确定要挖掘的硬负样本数量
num_entities = torch.sum(entity_mask).item()
num_hard_negatives = int(num_entities * self.hard_negative_ratio)
# 如果当前批次没有实体,则按固定比例选择负样本,避免数量为0
if num_hard_negatives == 0:
num_non_entities = torch.sum(non_entity_mask).item()
num_hard_negatives = int(num_non_entities * 0.1)
# 从非实体损失中选出最大的 top-k 个作为硬负样本
topk_losses, _ = torch.topk(non_entity_loss.view(-1), k=num_hard_negatives)
# 计算硬负样本的平均损失
hard_negative_loss = torch.mean(topk_losses)
# 结合实体损失和硬负样本损失
total_loss = self.entity_weight * entity_loss + 1.0 * hard_negative_loss
return total_loss, entity_loss.detach(), hard_negative_loss.detach()
|
这个类封装了所有与损失计算相关的逻辑。它会返回一个元组 (总损失, 实体损失, 非实体损失),便于我们在训练日志中观察不同部分损失的变化情况。
4.2.2 硬负样本挖掘实现细节
在 _hard_negative_mining 的实现中,有一个需要特别注意的细节:torch.topk 函数要求 k 的值不能超过输入张量的维度大小。在此场景中,如果计算出的 num_hard_negatives 超过了当前批次中非实体 O 的总数,就会引发运行时错误。
同时,需要将二维的 non_entity_loss 展平(view(-1))成一维,以确保 topk 是在所有非实体样本中寻找损失最大的 k 个。下面是修正后的关键代码片段:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| # code/C8/src/loss/ner_loss.py
def _hard_negative_mining(self, logits, labels):
# ... (省略实体损失计算)
non_entity_mask = (labels == 0).float()
non_entity_loss = loss_per_token * non_entity_mask
num_hard_negatives = int(torch.sum(entity_mask).item() * self.hard_negative_ratio)
if num_hard_negatives == 0:
num_hard_negatives = int(torch.sum(non_entity_mask).item() * 0.1)
# 关键修改:将损失展平为一维
non_entity_loss_flat = non_entity_loss.view(-1)
# 关键修改:确保 k 不超过非实体 token 的总数
num_non_entities = torch.sum(non_entity_mask).item()
k = min(num_hard_negatives, num_non_entities)
if k == 0: # 如果没有负样本可选,则损失为 0
non_ner_loss_mean = torch.tensor(0.0, device=logits.device)
else:
topk_losses, _ = torch.topk(non_entity_loss_flat, k=k)
non_ner_loss_mean = torch.mean(topk_losses)
total_loss = self.entity_weight * ner_loss_mean + 1.0 * non_ner_loss_mean
return total_loss, ner_loss_mean.detach(), non_ner_loss_mean.detach()
|
4.2.3 更新配置文件
接着,需要在 src/configs/configs.py 中添加几个参数,以便能够灵活地选择和配置损失函数。
1
2
3
4
5
6
7
8
9
10
11
12
13
| # code/C8/src/configs/configs.py
# ...
learning_rate: float = 1e-3
device: str = field(default_factory=lambda: 'cuda' if torch.cuda.is_available() else 'cpu')
# --- 损失函数参数 ---
loss_type: str = "weighted_ce" # 可选: "cross_entropy", "weighted_ce", "hard_negative_mining"
entity_loss_weight: float = 10.0 # 在 weighted_ce 和 hard_negative_mining 中, 给实体部分损失的权重
hard_negative_ratio: float = 0.5 # 在 hard_negative_mining 中, 负样本数量与正样本数量的比例
# --- 模型参数 ---
# ...
|
4.2.4 修改训练器
为了处理 NerLoss 返回的多个损失值,并优化训练日志,需要对 src/trainer/trainer.py 进行升级。
主要的修改点包括:
- 仅用“主损”反向传播(若为元组损失,取
loss[0])。 - 训练阶段累计并返回三元组(总损/实体/非实体)。
- 评估阶段用“主损”统计验证集
loss。 - 保存最优模型以
{'model_state_dict': ...} 方式,便于 06_predict.py 直接加载。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
| # code/C8/src/trainer/trainer.py
# ... (省略未修改部分)
from tqdm import tqdm
import os
import torch
class Trainer:
# ... (省略 __init__ 等)
def fit(self, epochs):
os.makedirs(self.output_dir, exist_ok=True)
best_metric = float('-inf') # 优先最大化 F1
for epoch in range(1, epochs + 1):
print(f"--- Epoch {epoch}/{epochs} ---")
train_losses = self._train_one_epoch()
# 支持元组损失的日志打印(总损/实体/非实体)
if isinstance(train_losses, tuple):
train_loss_str = (
f"Train Total Loss: {train_losses[0]:.4f}, "
f"NER Loss: {train_losses[1]:.4f}, "
f"Non-NER Loss: {train_losses[2]:.4f}"
)
else:
train_loss_str = f"Train Total Loss: {train_losses:.4f}"
print(train_loss_str)
eval_metrics = self._evaluate()
eval_metrics_str = ", ".join([f"{k}: {v:.4f}" for k, v in eval_metrics.items()])
print(f"Validation Metrics: {eval_metrics_str}")
# 以验证集 F1 作为保存准则;无 F1 时回退用 loss
is_best = False
if 'f1' in eval_metrics:
if eval_metrics['f1'] > best_metric:
best_metric = eval_metrics['f1']
is_best = True
else:
if best_metric == float('-inf'):
best_metric = float('inf')
if eval_metrics['loss'] < best_metric:
best_metric = eval_metrics['loss']
is_best = True
if is_best:
print(f"New best model found! Saving to {self.output_dir}")
# 以字典方式保存,键为 'model_state_dict',便于 06_predict.py 加载
torch.save({'model_state_dict': self.model.state_dict()},
os.path.join(self.output_dir, "best_model.pth"))
def _train_one_epoch(self):
self.model.train()
total_loss_sum = 0
total_ner_loss = 0
total_non_ner_loss = 0
custom_loss_used = False
for batch in tqdm(self.train_loader, desc=f"Training Epoch"):
outputs = self._train_step(batch)
loss = outputs['loss']
if isinstance(loss, tuple):
# 支持元组损失(总损/实体/非实体)并分别累计
custom_loss_used = True
total_loss_sum += loss[0].item()
total_ner_loss += loss[1].item()
total_non_ner_loss += loss[2].item()
else:
total_loss_sum += loss.item()
if custom_loss_used:
# 返回三元组 (avg_total, avg_ner, avg_non_ner)
avg_loss = total_loss_sum / len(self.train_loader)
avg_ner_loss = total_ner_loss / len(self.train_loader)
avg_non_ner_loss = total_non_ner_loss / len(self.train_loader)
return avg_loss, avg_ner_loss, avg_non_ner_loss
else:
return total_loss_sum / len(self.train_loader)
def _train_step(self, batch):
# ... (省略前向部分)
logits = self.model(token_ids=batch['token_ids'], attention_mask=batch['attention_mask'])
loss = self.loss_fn(logits.permute(0, 2, 1), batch['label_ids'])
# 仅用主损进行反向传播(元组时取 loss[0])
main_loss = loss[0] if isinstance(loss, tuple) else loss
self.optimizer.zero_grad()
main_loss.backward()
self.optimizer.step()
return {'loss': loss, 'logits': logits}
def _evaluate(self):
if self.dev_loader is None:
return None
self.model.eval()
total_loss = 0
all_logits, all_labels, all_attention_mask = [], [], []
with torch.no_grad():
for batch in tqdm(self.dev_loader, desc="Evaluating"):
outputs = self._evaluation_step(batch)
loss = outputs['loss']
# 验证 loss 也使用主损统计
main_loss = loss[0] if isinstance(loss, tuple) else loss
total_loss += main_loss.item()
all_logits.append(outputs['logits'].cpu())
all_labels.append(batch['label_ids'].cpu())
all_attention_mask.append(batch['attention_mask'].cpu())
metrics = {}
if self.eval_metric_fn:
metrics = self.eval_metric_fn(all_logits, all_labels, all_attention_mask)
metrics['loss'] = total_loss / len(self.dev_loader)
return metrics
# ... (其余方法保持不变)
|
4.2.5 集成到主函数
最后一步,在 05_train.py 中根据配置来实例化对应的损失函数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| # code/C8/05_train.py
# ...
from src.loss.ner_loss import NerLoss # 导入新模块
# ... (在main函数中)
# --- 3. 初始化模型、优化器、损失函数 ---
model = BiGRUNerNetWork(...)
optimizer = torch.optim.AdamW(...)
# 根据配置选择损失函数
if config.loss_type == "cross_entropy":
loss_fn = nn.CrossEntropyLoss(ignore_index=-100)
else:
loss_fn = NerLoss(
loss_type=config.loss_type,
entity_weight=config.entity_loss_weight,
hard_negative_ratio=config.hard_negative_ratio
)
# ...
|
完成以上步骤后,就可以通过简单地修改 configs.py 中的 loss_type 参数,来切换不同的损失函数策略,并观察它们对模型训练效果的影响。例如,将 loss_type 设置为 "weighted_ce",然后重新运行 05_train.py,会看到训练日志中包含了实体和非实体各自的损失值。
4.2.6 解读验证集损失
在使用自定义损失函数(尤其是 weighted_ce 和 hard_negative_mining)时,你可能会观察到一个现象:验证集上的 F1 分数在稳步提升,但 loss 值却停滞不前甚至上升。这是一个正常且符合预期的现象。
这是因为 Trainer 在评估阶段同样使用了这个自定义的、加权的损失函数来计算验证集 loss。这个 loss 主要反映的是训练目标的优化情况,而不是一个标准的评估指标。
- 权重影响: 由于实体部分的损失被赋予了很高的权重(例如
entity_loss_weight=10.0),少数几个实体相关的错误就会导致 loss 值大幅波动或居高不下。 - 硬负样本挖掘影响:
hard_negative_mining 策略会动态地聚焦于模型最容易搞错的那些非实体 O 标签。随着训练的进行,简单的负样本损失会降低,但模型会转而面对更“棘手”的硬样本,导致计算出的 non_ner_loss 可能不会持续下降。
因此,当使用这些高级损失策略时,验证集 loss 不再是衡量模型好坏的主要标准。应将注意力更多地放在能够直接反映任务最终目标的指标上,对于 NER 任务而言,这个指标就是实体级别的 F1 分数。这也是 Trainer 将 F1 作为保存最佳模型依据的原因。
五、优化训练工作流
在我们实现了核心的训练、评估与推理流程之后,一个健robustness的训练框架还需要更多辅助功能来应对真实场景中的各种挑战。本节将介绍如何为 Trainer 集成三项关键的实用功能:可视化日志、提前停止和断点续训,让训练过程更加可控、高效和可靠。
5.1 训练过程可视化
纯文本的训练日志虽然直接,但难以洞察模型训练的全局动态。为了更直观地监控训练过程,例如观察损失是否平稳下降、验证集 F1 是否持续提升,以及模型是否出现过拟合迹象,可以集成 TensorBoard 来实现可视化;同时,为提高结果的可复现性,建议在训练开始前固定随机数种子。
为了将日志记录功能模块化,可以创建一个专门的 TensorBoardLogger 类来封装所有与 SummaryWriter 相关的操作。
创建 TensorBoardLogger 类:
在 src/utils/ 目录下创建 logger.py 文件。这个类将负责 SummaryWriter 的初始化、指标记录和关闭。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| # code/C8/src/utils/logger.py
from torch.utils.tensorboard import SummaryWriter
class TensorBoardLogger:
def __init__(self, log_dir):
# 如果提供了日志目录,则初始化 SummaryWriter
self.writer = SummaryWriter(log_dir) if log_dir else None
def log_metrics(self, metrics, step, prefix):
# 如果 writer 未初始化,则不执行任何操作
if self.writer is None: return
# 根据 metrics 类型(元组或字典)以不同方式记录
if isinstance(metrics, tuple):
self.writer.add_scalar(f"{prefix}/Total_Loss", metrics[0], step)
if len(metrics) > 1:
self.writer.add_scalar(f"{prefix}/NER_Loss", metrics[1], step)
self.writer.add_scalar(f"{prefix}/Non-NER_Loss", metrics[2], step)
elif isinstance(metrics, dict):
for k, v in metrics.items():
self.writer.add_scalar(f"{prefix}/{k.capitalize()}", v, step)
def close(self):
# 确保在训练结束时关闭 writer,将所有挂起的事件写入磁盘
if self.writer:
self.writer.close()
|
在 configs.py 中添加配置:
1
2
3
4
5
6
7
8
9
| # code/C8/src/configs/configs.py
# ... (省略)
class NerConfig:
# ... (省略)
# --- 增强功能参数 ---
output_summary_dir: str = "output/logs" # TensorBoard 日志输出路径
seed: int = 42 # 随机数种子(用于可复现性)
# ... (省略)
|
在 Trainer 中使用 TensorBoardLogger:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| # code/C8/src/trainer/trainer.py
from src.utils.logger import TensorBoardLogger
class Trainer:
def __init__(self, ..., summary_writer_dir=None, ...):
# ... (省略其他初始化)
# 初始化日志记录器
self.logger = TensorBoardLogger(summary_writer_dir)
def fit(self, epochs):
for epoch in range(self.start_epoch, epochs + 1):
# ... (训练与评估)
# 在每个 epoch 结束后调用 logger 记录训练和验证指标
self.logger.log_metrics(train_losses, epoch, "Train")
self.logger.log_metrics(eval_metrics, epoch, "Validation")
# 训练结束后关闭 logger
self.logger.close()
|
添加随机数种子
为了使可视化对比与调参更稳定可复现,建议在训练启动时固定随机数种子,读取 configs.py 中新增的 seed 配置。
在 05_train.py 中添加工具函数并调用:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| # code/C8/05_train.py
# ... 省略导入
def seed_everything(seed: int = 42):
torch.manual_seed(seed)
if torch.cuda.is_available():
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
def main():
# 训练前设置随机种子(读取 configs.py 的 seed)
seed_everything(getattr(config, 'seed', 42))
# ... 后续组件初始化与训练
|
5.2 早停实现
为了让这个逻辑更清晰且可复用,可将其封装到一个独立的 EarlyStopping 类中,这个类就像一个“回调”一样,在每个 epoch 结束时被 Trainer 调用来检查是否需要停止。
创建 EarlyStopping 工具类:
在 src/utils/ 目录下创建一个新文件 early_stop.py。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| # code/C8/src/utils/early_stop.py
import numpy as np
class EarlyStopping:
def __init__(self, patience=5, verbose=False, delta=0, monitor='f1', mode='max'):
self.patience = patience # 耐心值:连续多少轮性能没有提升则停止
self.verbose = verbose # 是否打印日志
self.counter = 0 # 计数器
self.best_score = None # 历史最佳分数
self.early_stop = False # 提前停止标志
self.val_metric_best = np.inf if mode == 'min' else -np.inf # 根据模式初始化最佳指标
self.delta = delta # 容忍的性能下降范围
self.monitor = monitor # 监控的指标
self.mode = mode # 'max' 或 'min'
def __call__(self, val_metric):
# 根据 'mode' 调整分数计算方式
score = -val_metric if self.mode == 'min' else val_metric
if self.best_score is None:
self.best_score = score
# 如果当前分数没有超过(最佳分数 + delta),则增加计数器
elif score < self.best_score + self.delta:
self.counter += 1
if self.verbose:
print(f'EarlyStopping counter: {self.counter} out of {self.patience}')
if self.counter >= self.patience:
self.early_stop = True
# 如果分数有提升,则更新最佳分数并重置计数器
else:
self.best_score = score
self.counter = 0
return self.early_stop
|
在 configs.py 中添加配置:
1
2
3
4
| # code/C8/src/configs/configs.py
# ... (省略)
early_stopping_patience: int = 5 # 提前停止的耐心轮数
|
在 Trainer 中集成 EarlyStopping 实例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| # code/C8/src/trainer/trainer.py
from src.utils.early_stop import EarlyStopping
class Trainer:
def __init__(self, ..., early_stopping_patience=5, ...):
# ... (省略其他初始化)
# 初始化 EarlyStopping 回调
self.early_stopping = EarlyStopping(
patience=early_stopping_patience,
verbose=True,
monitor='f1'
)
def fit(self, epochs):
for epoch in range(self.start_epoch, epochs + 1):
# ... (训练与评估)
current_metric = eval_metrics.get('f1', -eval_metrics.get('loss', float('inf')))
# ... (保存最佳模型逻辑)
# 调用 early_stopping 实例判断是否需要停止
if self.early_stopping(current_metric):
print("Early stopping triggered.")
break # 跳出训练循环
|
5.3 实现断点续训
对于需要数小时甚至数天的长时间训练任务,意外中断(如断电、程序崩溃)是常见风险。从头开始训练会造成巨大的时间浪费。断点续训 (Checkpointing & Resuming) 机制允许我们保存训练过程中的完整状态(包括模型权重、优化器状态和当前轮数),并在需要时从中恢复,继续训练。
实现此功能主要分为三步:首先添加配置项,然后在 Trainer 中构建核心的保存与恢复逻辑,最后在主训练脚本中启用它。
在 configs.py 中添加配置:
首先,在 NerConfig 中增加一个 resume_checkpoint 字段,用于指定需要恢复的检查点文件路径。如果它为 None,则从头开始训练。
1
2
3
4
| # code/C8/src/configs/configs.py
# ... (其他配置)
# 用于恢复训练的检查点路径, e.g., "output/last_model.pth"
resume_checkpoint: str = None
|
为 Trainer 新增保存与恢复能力:
接下来,为 Trainer 类赋予保存和恢复检查点的能力。这包括新增两个核心方法 _save_checkpoint 和 _resume_checkpoint,并修改 __init__ 和 fit 方法来调用它们。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| # code/C8/src/trainer/trainer.py
class Trainer:
def __init__(self, ..., resume_checkpoint=None, ...):
# ...
self.start_epoch = 1 # 默认从第一轮开始
# ...
# 如果指定了检查点路径,则调用恢复方法
if resume_checkpoint:
self._resume_checkpoint(resume_checkpoint)
def fit(self, epochs):
# 使用 self.start_epoch 替换固定的 `1`,以支持从指定轮数开始
for epoch in range(self.start_epoch, epochs + 1):
# ... (训练和评估)
# --- 保存逻辑 ---
is_best = False
current_metric = eval_metrics.get('f1', -eval_metrics.get('loss', float('inf')))
if current_metric > self.best_metric:
self.best_metric = current_metric
is_best = True
# 在每轮结束后都保存检查点
self._save_checkpoint(epoch, is_best)
# ... (早停逻辑)
# 调用 early_stopping 实例判断是否需要停止
if self.early_stopping(current_metric):
print("Early stopping triggered.")
break # 跳出训练循环
|
这里有几个关键点:
__init__ 中会检查 resume_checkpoint,如果提供了路径,就调用恢复方法。fit 方法的循环 for epoch in range(1, epochs + 1) 需要修改为 for epoch in range(self.start_epoch, epochs + 1),以便从恢复的轮数继续训练。fit 方法在每轮结束时调用 _save_checkpoint 来保存当前状态。
在 05_train.py 中启用并校验:
最后,在主训练脚本中,我们需要在初始化 Trainer 之前,先检查配置文件中 resume_checkpoint 指定的路径是否有效。如果路径无效,就将其置为 None,以确保 Trainer 能够安全地从头开始训练,而不是因找不到文件而报错。
1
2
3
4
5
6
7
8
9
10
11
12
13
| # code/C8/05_train.py
# ... (省略前半部分)
# 在初始化 Trainer 前,检查检查点文件是否存在
if config.resume_checkpoint and not os.path.exists(config.resume_checkpoint):
print(f"Checkpoint file not found: {config.resume_checkpoint}. Starting training from scratch.")
config.resume_checkpoint = None # 设为 None, 避免 Trainer 报错
trainer = Trainer(
# ...
resume_checkpoint=config.resume_checkpoint
)
|
5.4 更新主训练脚本
完成了对 Trainer 的升级并将日志、早停等功能模块化后,最后一步是在主训练脚本 05_train.py 中,将相应的配置参数传递给 Trainer 实例,从而正式启用这些新功能。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| # code/C8/05_train.py
# ... (省略前半部分代码)
# --- 5. 初始化并启动训练器 ---
trainer = Trainer(
model=model,
optimizer=optimizer,
loss_fn=loss_fn,
train_loader=train_loader,
dev_loader=dev_loader,
eval_metric_fn=eval_metric_fn,
output_dir=config.output_dir,
device=config.device,
# 传入新增的配置参数,以启用对应的功能
summary_writer_dir=config.output_summary_dir, # TensorBoard 日志目录
early_stopping_patience=config.early_stopping_patience, # 早停耐心轮数
resume_checkpoint=config.resume_checkpoint # 断点续训的检查点路径
)
# ... (省略后半部分代码)
|
本章小结
回顾整个流程,一个完整的命名实体识别项目已经从零开始被系统性地构建出来。整个过程贯穿了从数据处理、模型构建到训练优化与最后推理的全流程:
- 数据处理与准备:首先解析原始的 CMeEE 数据集,构建了全局统一的
BMES 标签映射 (categories.json) 和字符级词汇表 (vocabulary.json),并最终封装成一个高效、可复用的 DataLoader,为模型训练提供了标准化的数据输入。 - 模型构建与训练框架:设计并实现了一个基于
Bi-GRU 的序列标注模型,并围绕它打造了一个结构清晰、组件化的训练框架。通过将模型、数据加载器、分词器、评估指标等核心功能解耦,构建了一个易于维护和扩展的 Trainer 类。 - 推理与工作流优化:实现从模型输出到结构化实体的解码逻辑,并将其封装成一个开箱即用的
NerPredictor 推理器。同时,为了提升训练框架的健壮性和实用性,还集成了自定义损失函数来应对数据不均衡问题,并引入了 TensorBoard 可视化日志、提前停止(Early Stopping)和断点续训(Checkpointing)等高级功能。
通过以上步骤,不仅实现了一个能跑通的 NER 模型,更重要的是搭建起了一套模块化、功能完备的 NER 项目脚手架。尽管当前基线模型的性能可能还有提升空间,但这个框架为后续探索更先进的模型(如 BERT)、尝试更复杂的策略提供了不错的起点。
参考文献
- Lample, G., Ballesteros, M., Subramanian, S., Kawakami, K., & Dyer, C. (2016). Neural Architectures for Named Entity Recognition.↩︎
- Sohrab, M. G., & Miwa, M. (2018). Deep Exhaustive Model for Nested Named Entity Recognition.↩︎
- Eberts, M., & Ulges, A. (2019). Span-based Joint Entity and Relation Extraction with Transformer Pre-training (SpERT).↩︎
- Vinyals, O., Fortunato, M., & Jaitly, N. (2015). Pointer Networks.↩︎
- Shen, Y., Ma, X., Tan, Z., Zhang, S., Wang, W., & Lu, W. (2021). Locate and Label: A Two-stage Identifier for Nested Named Entity Recognition.↩︎