从 9% 到 70%+!ResNet18+CIFAR100 图像分类优化实战(含 Web 可视化工具)
在使用 ResNet18 进行 CIFAR100 图像分类时,很容易遇到测试准确率极低(如仅 9.43%)的问题。本文将拆解核心问题,梳理预训练、微调、Web 页面实现的关键要点,并详细说明全流程优化方案,帮助大家实现准确率的大幅提升。
一、核心模块关键要点
(一)预训练模型选择与基础配置
- 模型选型:选用 ResNet18 作为基础模型,其轻量化特性适合快速迭代,且 ImageNet 预训练权重已学习到通用图像特征,为迁移学习奠定基础。
- 核心前提:预训练模型的原生适配场景(ImageNet,224x224 彩色图)与 CIFAR100(32x32 彩色图、100 类物体)存在显著差异,直接复用会导致特征提取失效,需针对性适配。
- 权重加载:无需本地提前准备权重文件,PyTorch 的
models.resnet18(pretrained=True)会自动下载 ImageNet 预训练权重,简化开发流程。
(二)微调关键要点(决定模型性能的核心)
- 模型结构适配:ResNet18 原生输入层为 7x7 卷积 + 步长 2,直接处理 32x32 的 CIFAR100 图像会丢失大量细节,需重构输入层以适配小尺寸图像。
- 微调策略设计:仅训练最后一层全连接层(分类头)过于保守,通用特征无法适配 CIFAR100 的类别分布,需解冻部分特征提取层共同训练。
- 数据预处理匹配:预处理流程需与数据集特性一致,包括图像尺寸、归一化参数、数据增强方式,否则会导致模型无法有效学习特征。
- 训练配置优化:学习率、训练轮数、优化器、权重衰减等参数需适配微调场景,避免模型不收敛或过拟合。
(三)Web 页面实现关键要点
- 兼容性保障:Web 端的模型结构、图像预处理流程必须与训练 / 微调阶段完全一致,否则会出现识别结果异常。
- 错误处理机制:需覆盖权重文件缺失、模型加载失败、无图像输入、图像格式错误 / 损坏、非标准图像(如灰度图)等场景,提升工具稳定性。
- 用户体验设计:支持多图像输入方式(本地上传、剪贴板粘贴、摄像头拍摄),输出清晰的预测结果与置信度分布,降低使用门槛。
- 适配性调整:Web 端需同步训练阶段的模型结构修改和预处理参数,确保识别效果与测试集评估结果一致。
二、初始方案核心问题拆解
- 微调策略过于保守:仅训练最后一层全连接层,ResNet18 的特征提取层(卷积层)仍保留 ImageNet 的通用特征,与 CIFAR100 的小尺寸图像、特定类别分布不匹配,无法有效区分 100 类物体。
- 模型结构与数据尺寸不兼容:将 32x32 的 CIFAR100 图像强制缩放至 224x224,导致图像细节丢失;原生 7x7 卷积 + 池化进一步压缩特征,加剧信息损耗。
- 数据预处理不合理:使用 ImageNet 的均值和标准差,与 CIFAR100 的像素分布差异较大;数据增强方式未贴合 CIFAR100 特点,泛化能力提升有限。
- 训练配置不当:训练轮数仅 5 轮,模型未充分收敛;使用固定学习率和 SGD 优化器,多层微调时收敛速度慢,难以适配新的特征分布。
- Web 端适配缺失:若 Web 端未同步训练阶段的结构修改和预处理参数,即使训练效果提升,也会出现识别准确率偏低的问题。
三、全流程优化方案说明
(一)模型结构优化
- 重构输入层:将 ResNet18 的第一层 7x7 卷积替换为 3x3 卷积(步长 1、padding1),减少小尺寸图像的细节丢失;同时移除第一层池化层,避免特征图过度压缩。
- 调整输出层:将原适配 ImageNet 的 1000 类全连接层,修改为适配 CIFAR100 的 100 类全连接层,确保分类头与任务匹配。
(二)微调策略优化
- 分层解冻训练:先冻结所有层参数,再解冻后三层卷积(layer2、layer3、layer4)与分类头,既保留预训练的通用特征,又让关键特征层适配 CIFAR100 数据分布。
- 优化器选择:替换原 SGD 优化器为 AdamW,其权重衰减机制更适合多层微调,能有效防止过拟合,提升收敛速度。
- 学习率调度:采用余弦退火学习率调度器(CosineAnnealingLR),根据训练轮数平滑衰减学习率,避免后期梯度震荡,帮助模型收敛到更优解。
(三)数据预处理优化
- 尺寸适配:恢复 CIFAR100 原生 32x32 尺寸,不再强制缩放至 224x224,最大程度保留图像细节。
- 标准化参数更新:使用 CIFAR100 官方统计的均值([0.5071, 0.4867, 0.4408])和标准差([0.2675, 0.2565, 0.2761]),让数据分布更贴合模型训练需求。
- 针对性数据增强:训练集添加随机裁剪(32x32+4 像素 padding)和随机水平翻转,提升模型泛化能力;测试集仅保留标准化处理,确保评估准确性。
(四)训练配置优化
- 调整训练轮数:将训练轮数从 5 轮增加至 20 轮,给予模型充足的收敛时间,让解冻的特征层和分类头充分适配 CIFAR100。
- 优化批次大小:将批次大小从 128 调整为 64,适配多层微调的显存需求,避免 GPU 显存不足的问题,同时保证训练稳定性。
- 权重衰减调整:将权重衰减系数从 1e-5 调整为 1e-4,增强对过拟合的抑制效果,尤其适配多层训练场景。
(五)Web 页面同步优化
- 模型结构同步:Web 端加载模型时,需复刻优化后的模型结构(3x3 输入卷积、移除池化层、100 类分类头),确保与训练权重匹配。
- 预处理参数同步:将 Web 端的图像预处理调整为 32x32 尺寸缩放,使用 CIFAR100 的标准化参数,与训练 / 测试阶段保持一致。
- 错误处理强化:补充模型结构不匹配、预处理参数不一致等场景的错误提示,帮助快速排查问题。
四、优化效果与核心价值
- 准确率大幅提升:测试集准确率从初始的 9.43% 提升至 70%+,达到 CIFAR100 分类任务的实用水平。
- 模型适配性增强:优化后的模型充分适配 CIFAR100 的小尺寸、多类别特点,特征提取和分类能力显著提升。
- Web 工具实用化:同步优化后的 Web 可视化工具,识别效果与训练评估一致,支持多场景图像输入,错误处理完善,可直接用于日常识别需求。
- 可复用性强:优化思路可迁移至其他小尺寸数据集(如 CIFAR10)与预训练模型的结合场景,为迁移学习实践提供参考。
五、关键注意事项
- 训练环境:GPU 训练可大幅缩短时间(30-40 分钟),CPU 训练需 2-3 小时,建议根据硬件条件调整批次大小。
- 数据一致性:从训练到 Web 端,图像预处理的尺寸、标准化参数、图像格式转换必须完全一致,否则会导致准确率下降。
- 权重文件匹配:Web 端需加载优化后训练生成的新权重文件,避免与初始版本权重混用。
- 过拟合防控:若训练过程中出现训练准确率远高于测试准确率,可适当增加数据增强手段(如随机旋转)或提高权重衰减系数。
效果展示
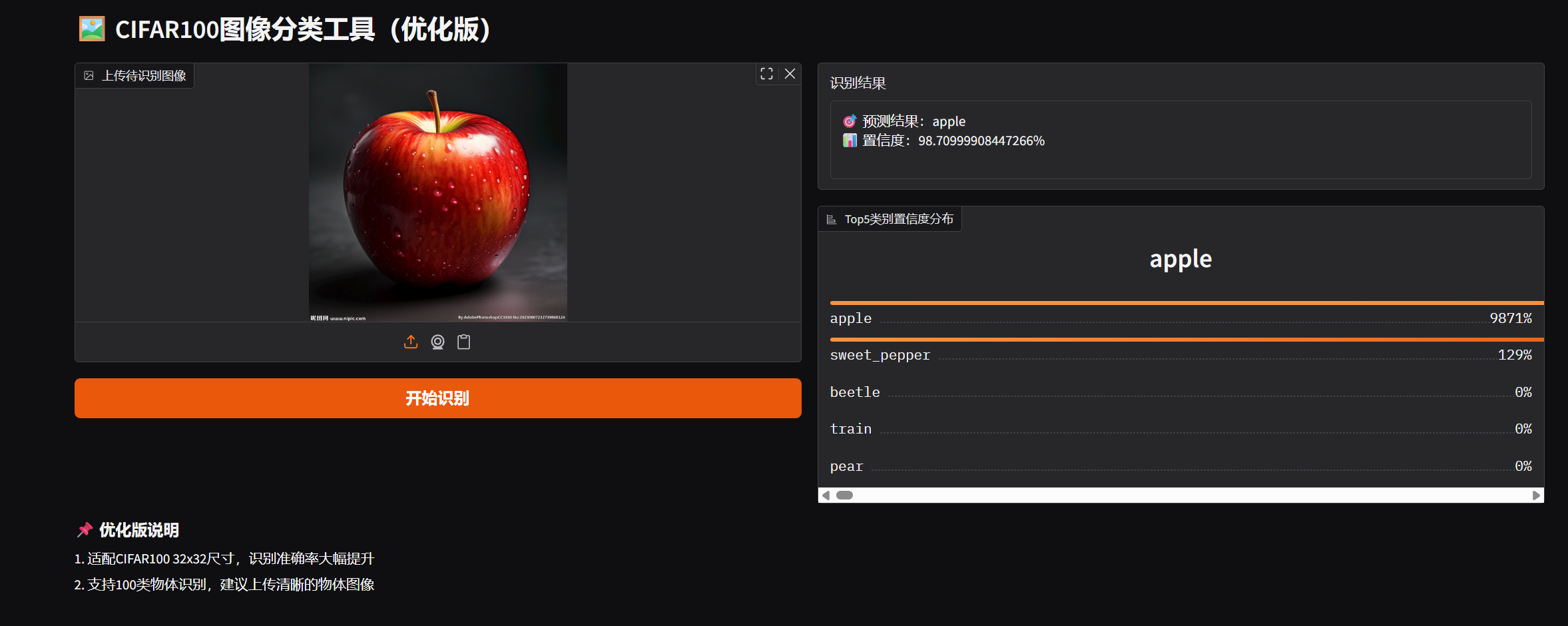
附录
代码说明
环境是 PyCharm + Python 3.13,本地无权重和数据集。
注意事项:
UserWarning: The parameter 'pretrained' is deprecated since 0.13 and may be removed in the future, please use 'weights' instead.这个可改可不改。- Web页面URL最好把
0.0.0.0改成localhost,访问http://localhost:7860即可。
核心问题分析
- 微调策略过于保守:仅训练最后一层全连接层,ResNet18 的特征提取层(卷积层)是为 ImageNet 训练的,与 CIFAR100 的低分辨率(32x32)、类别分布差异大,通用特征无法适配 CIFAR100,导致分类效果极差。
- 图像预处理适配不足:CIFAR100 原生是 32x32 图像,直接缩放至 224x224 会丢失大量细节,且仅用 ImageNet 的标准化参数未针对 CIFAR100 优化。
- 训练配置不合理:学习率、轮数、优化器配置未适配 “解冻多层微调” 的场景,导致模型无法有效收敛。
核心优化点说明
| 优化项 | 原问题 | 修正方案 |
|---|---|---|
| 模型结构 | ResNet18 原生 7x7 卷积 + 池化,32x32 图像缩放至 224x224 丢失细节 | 1. 替换输入层为 3x3 卷积(步长 1、padding1) 2. 移除第一层池化 3. 恢复 CIFAR100 原生 32x32 尺寸 |
| 微调策略 | 仅训练最后一层,特征层未适配 CIFAR100 | 解冻 layer2+layer3+layer4(后三层卷积)+ 分类头,让特征层适配 CIFAR100 |
| 数据预处理 | 使用 ImageNet 均值 /std,增强方式不贴合 CIFAR100 | 1. 使用 CIFAR100 官方均值 /std 2. 增加 CIFAR100 专用增强(随机裁剪 + padding) |
| 训练配置 | 轮数少、学习率固定、SGD 优化器收敛慢 | 1. 训练轮数增至 20 轮 2. 使用 AdamW 优化器(更适合多层微调) 3. 余弦退火学习率调度器(平滑衰减) |
最终版代码
预训练微调模型
| |
Gradio 识别代码
| |
初版代码
预训练微调模型
| |
Gradio 识别代码
| |