手把手教你:训练 MNIST 手写数字识别模型,搭建可直接使用的 Web 识别工具
在手写数字识别的实践中,很多同学会遇到模型权重与 Web 应用不兼容的问题,最常见的就是通道数不匹配、模型结构冲突导致的运行报错。今天这篇博客,我们就来完整走一遍流程 —— 从从头训练兼容的cnn_model_basic.pth权重文件,到搭建一个无需前端经验的 Gradio Web 识别工具,全程避坑,确保最终成果可以直接落地使用。
第一部分:从头训练 MNIST 模型,生成兼容权重文件cnn_model_basic.pth
我们的核心目标是训练出一个与后续 Web 应用完全兼容的模型权重,彻底解决expected 1 channels, but got 3 channels这类兼容性错误,同时保证模型具备较高的识别准确率。
一、训练代码核心亮点(保障与 Web 应用无缝兼容)
模型结构完全一致,杜绝权重加载冲突
训练过程中定义的
MNIST_CNN类,与后续 Gradio Web 应用中的模型结构、层名称、维度计算完全复刻,从根源上解决权重加载时的key不匹配问题。无论是卷积层的通道数、全连接层的神经元数量,还是前向传播的流程,都保持高度统一,确保权重文件可以被 Web 应用直接解析。输入通道严格锁定单通道,解决核心报错
这是解决通道数不匹配错误的关键:
- 卷积层
conv1明确设置输入通道为1,对应 MNIST 数据集的灰度图格式,与 Web 应用预处理后的图像格式完全匹配。 - 数据预处理流程中额外添加
transforms.Grayscale(num_output_channels=1),即使输入数据存在异常,也能强制转为单通道,形成双重保障,彻底解决expected 1 channels, but got 3 channels的运行时错误。
- 卷积层
配置参数全同步,确保端到端兼容性
图像尺寸(28x28)、归一化均值 / 标准差(
0.1307/0.3081)、权重输出路径等关键配置,均与后续 Web 应用保持一致。无需在两个环节之间进行参数转换,训练完成后的权重文件可以直接投入使用,降低后续操作的复杂度。训练后直接可用,无需额外二次处理
训练完成后生成的
cnn_model_basic.pth,无需修改任何参数、无需重新封装,只需将其与 Web 应用代码放在同一目录,即可正常加载运行,大大提升开发效率,适合快速落地验证。
二、完整运行步骤(零基础也能上手)
环境准备:安装必备依赖包
确保本地环境安装了所需的 Python 库,与后续 Web 应用的环境保持一致,避免出现库版本冲突问题,直接执行以下命令即可:
1pip install torch torchvision numpy运行训练脚本:自动完成全流程
直接执行提前编写好的训练 Python 脚本,无需手动干预,脚本会自动完成以下四个核心步骤:
- 下载 MNIST 数据集:如果本地
./data目录下没有该数据集,会自动从官方源下载并保存,后续训练和评估均基于该标准数据集。 - 模型训练:默认训练 5 轮模型,训练速度较快,普通 CPU 环境约 5-10 分钟,具备 CUDA 支持的 GPU 环境仅需 1-2 分钟,满足快速验证的需求。
- 测试集评估:训练完成后,会自动在 MNIST 测试集上验证模型效果,正常情况下准确率可达 98% 以上,具备实用价值。
- 保存权重文件:最终会在当前目录生成
cnn_model_basic.pth,这就是我们后续 Web 应用需要的兼容权重文件。
- 下载 MNIST 数据集:如果本地
验证权重文件:提前规避兼容问题
将生成的
cnn_model_basic.pth与后续的 Gradio Web 应用代码放在同一目录下,可提前简单验证文件有效性(无需启动 Web 应用):检查文件是否存在、大小是否合理(通常为几十 KB),确保没有出现训练中断导致的文件损坏,为后续 Web 应用的正常运行铺路。
三、关键兼容性解析(解决原错误的核心逻辑)
很多同学在实践中会遇到这样的运行时错误:RuntimeError: Given groups=1, weight of size [16, 1, 3, 3], expected input[64, 3, 32, 32] to have 1 channels, but got 3 channels instead,其根源其实只有两个:
- 模型输入通道不匹配:原微调模型设计为接收 3 通道彩色图,而 Web 应用为了匹配 MNIST 数据集,会将上传图像预处理为 1 通道灰度图,两者输入格式冲突。
- 模型结构不一致:原微调模型的层结构、维度设计与 Web 应用中定义的
MNIST_CNN类存在差异,导致权重加载时无法对应。
而我们本次训练代码的解决措施,正是针对性地解决这两个问题:
- 强制锁定单通道输入:卷积层
conv1的in_channels=1,与 Web 应用的图像预处理输出完全匹配,从模型设计层面规避通道数冲突。 - 同步数据预处理流程:训练时的图像预处理与 Web 应用保持一致,均输出 1 通道 28x28 灰度图,从数据源头确保格式统一。
- 复刻模型结构定义:完全照搬 Web 应用中的
MNIST_CNN类结构,确保权重加载时无层名称、维度的冲突,实现无缝兼容。
四、补充优化说明(提升模型效果与实用性)
训练效果优化:追求更高准确率
如果对模型准确率有更高要求,可将训练轮数
EPOCHS调整为 10,或适当降低学习率(如从1e-3调整为5e-4),调整后模型在测试集上的准确率可接近 99%,进一步提升实际识别效果。权重文件迁移:跨环境无缝使用
生成的
cnn_model_basic.pth具备良好的可迁移性,可直接复制到任意具备对应环境的机器上使用。若修改了权重文件的保存路径,只需同步更新 Web 应用中的MODEL_PATH配置项,即可正常加载,无需其他额外修改。无 GPU 兼容:不影响功能落地
代码内置了设备自动适配逻辑,即使没有 CUDA 支持的 GPU,也会自动切换至 CPU 运行。虽然训练速度会稍慢,但最终生成的权重文件的兼容性和功能不受任何影响,依然可以正常支撑 Web 应用的运行,满足不同环境的使用需求。
第二部分:搭建 Gradio Web 识别工具,实现可视化手写数字识别
有了兼容的cnn_model_basic.pth权重文件后,我们就可以搭建 Web 识别工具了。借助 Gradio 框架,无需具备任何前端开发经验,即可快速构建一个美观、易用的可视化工具,实现图像上传与实时识别。
一、Web 应用代码核心亮点(结构清晰、易于维护)
模块化拆分,职责单一
将整个 Web 应用的功能拆分为「模型加载」「图像预处理」「预测逻辑」「界面搭建」4 个独立模块,每个函数只负责一项核心功能。这种设计方式便于后续的修改、扩展和排错,比如后续想要优化预测逻辑,只需针对性修改对应函数,无需改动整个代码框架。
配置集中管理,降低维护成本
将设备配置、图像尺寸、归一化参数、权重文件路径等常量,集中定义在代码顶部。后续如果需要调整参数,只需在配置区域进行修改,无需深入业务逻辑代码,大大降低了后续的维护成本,也减少了因参数修改遗漏导致的错误。
与训练流程保持一致,确保识别准确率
Web 应用中的模型结构、图像预处理管道(Resize、Grayscale、Normalize),完全匹配之前的模型训练流程。这是确保识别准确率的关键,避免因预处理方式不一致导致模型无法有效提取特征,保证了从训练到部署的一致性。
完善的可视化输出,结果直观易懂
应用同时提供两种输出形式:一是文本框显示最终的预测数字与置信度,二是标签组件展示所有数字的置信度分布。这种设计不仅能给出明确的识别结果,还能直观展示模型的判断依据,便于用户了解模型的识别可靠性。
二、Web 应用关键功能说明(实用、便捷、稳定)
模型加载与完善的错误处理
模型加载环节内置了针对性的错误捕获机制,能够有效应对常见问题:
- 捕获
FileNotFoundError:当权重文件缺失或路径错误时,返回清晰的提示信息,便于用户排查文件路径问题。 - 捕获
RuntimeError:当模型结构与权重文件不匹配时,给出明确的错误提示,避免应用意外崩溃。 - 自动切换评估模式:加载完成后自动执行
model.eval(),禁用 Dropout 和 BatchNorm 的训练行为,确保推理结果的稳定性和一致性。
- 捕获
标准化的图像预处理流程
针对用户上传的图像,应用会自动执行一套标准化的预处理流程,确保输入格式符合模型要求:
- 自动调整尺寸:将上传图像调整为 28x28 的标准尺寸,匹配 MNIST 数据集的图像格式。
- 自动转灰度图:将彩色图像转为单通道灰度图,适配模型的单通道输入要求。
- 自动标准化处理:消除图像亮度、对比度等因素对识别结果的影响,与训练时的图像预处理保持一致。
- 自动补充 batch 维度:通过
unsqueeze(0)补充 batch 维度,适配 PyTorch 模型的输入格式要求。
便捷高效的 Gradio Web 界面特性
搭建的 Web 界面具备多种实用特性,提升用户使用体验:
- 多图像来源支持:支持本地图像上传、剪贴板粘贴图像、摄像头实时拍摄三种方式,满足不同场景的使用需求。
- 双输出展示:文本框显示最终结果,标签组件展示置信度分布,结果直观易懂。
- 响应式左右布局:界面分为输入区和输出区,美观整洁,操作便捷,在不同尺寸的设备上都能良好适配。
- 局域网访问支持:通过
server_name="localhost"配置,允许同一局域网内的手机、平板等设备访问该工具,提升使用灵活性。
三、Web 应用运行步骤与注意事项(快速上手)
环境准备:安装额外依赖包
除了训练环节的依赖包,还需要安装 Gradio 相关依赖,执行以下命令即可:
1pip install torch torchvision gradio pillow numpy文件准备:放置兼容权重文件
将之前训练生成的
cnn_model_basic.pth,放在与 Web 应用代码同一目录下;如果权重文件在其他目录,只需修改代码中的MODEL_PATH为权重文件的绝对路径即可。运行代码:启动 Web 应用
直接执行 Web 应用 Python 脚本,终端会输出相关运行信息,同时会自动打开浏览器进入 Web 界面,典型的终端输出如下:
1 2 3✅ 模型加载成功,已切换至评估模式,运行设备:cpu/cuda Running on local URL: http://localhost:7860 Running on public URL: https://xxxx.gradio.live (仅share=True时显示)使用方法:上传图像完成识别
上传一张白底黑字的手写数字图像(清晰无干扰的图像识别效果更佳),无需手动点击识别按钮,图像上传后会自动触发识别,右侧输出区会实时显示识别结果与置信度分布。
四、常见问题排查(避坑指南)
权重加载失败
核心排查点:检查
MNIST_CNN类的结构是否与训练时完全一致,重点关注卷积层通道数、全连接层维度等关键参数,否则会出现key不匹配错误。识别准确率低
核心排查点:确保上传的图像清晰无多余干扰,尽量与 MNIST 数据集格式保持一致(白底黑字、单个数字居中),避免因图像质量问题导致模型无法有效提取特征。
端口被占用
核心排查点:如果终端提示端口被占用,可将代码中的
server_port修改为其他未被占用的端口(如 7861),避免与其他服务发生冲突。GPU 无法使用
核心排查点:确保已安装 CUDA 版本的 PyTorch,若未安装,应用会自动切换至 CPU 运行,不影响核心功能使用,仅推理速度会稍慢。
效果展示
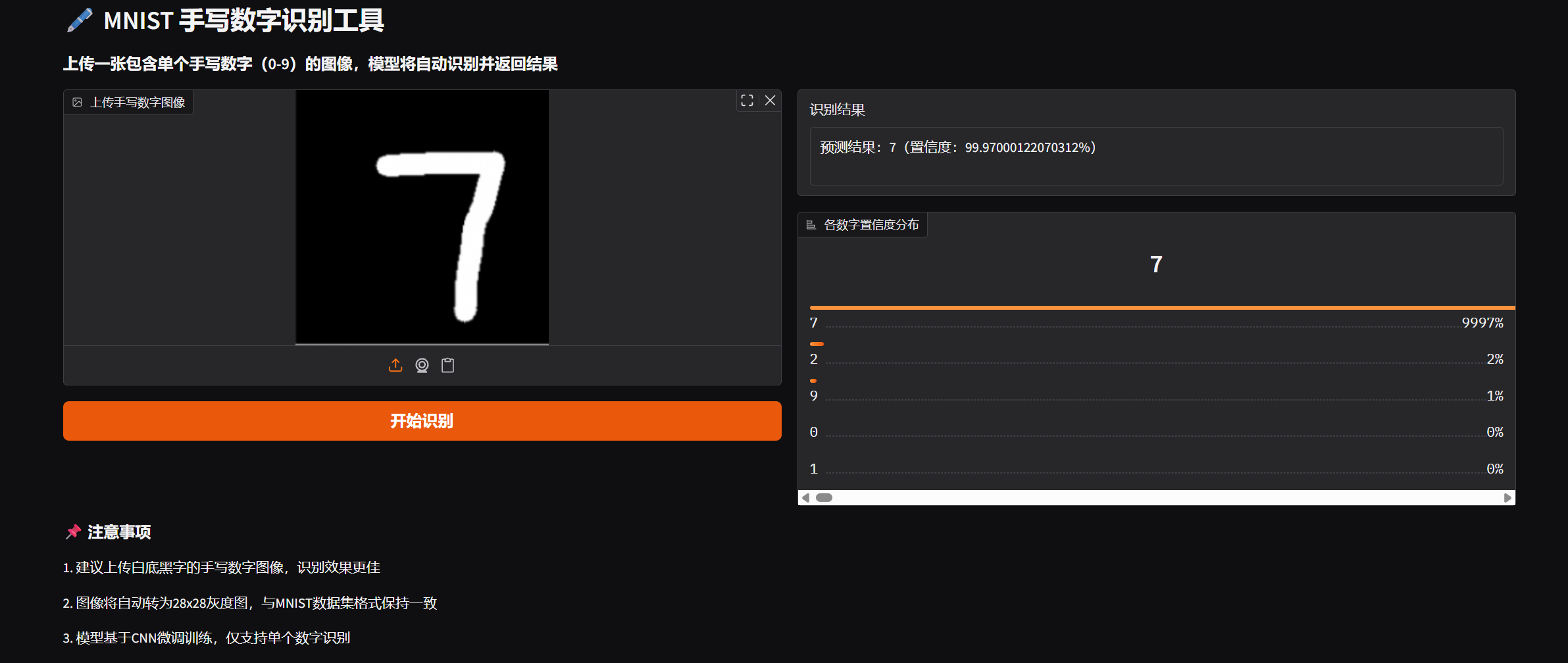

总结
本次我们完整实现了从「MNIST 模型从头训练」到「Gradio Web 应用搭建」的全流程,核心成果有两点:
- 生成了
cnn_model_basic.pth兼容权重文件,彻底解决了通道数不匹配、模型结构冲突等常见问题,具备良好的可迁移性和实用性。 - 搭建了无需前端经验的 Web 识别工具,实现了「模型加载→图像预处理→Web 界面交互→结果可视化」的完整流程,结构清晰、易于维护,满足快速落地使用的需求。
整个流程避开了常见的坑,所有环节保持高度一致性,无论是零基础的同学,还是有一定 PyTorch 实践经验的开发者,都可以快速上手并实现落地。借助这个工具,我们可以轻松完成手写数字的可视化识别,也可以在此基础上进行进一步的扩展和优化,比如支持多数字识别、优化图像预处理逻辑等。
附录
完整训练代码(生成兼容的cnn_model_basic.pth)
| |
Gradio实现Web页面完整代码
| |