PDF转Markdown工具
前言
在大语言模型(LLM)迅速发展的时代,文档处理和转换变得尤为重要。当我们需要将各种格式的文档(如 PDF、Word、PowerPoint 等)输入到 LLM 中进行分析或处理时,首先需要将这些文档转换为文本格式。然而,简单的文本转换往往会丢失文档的结构信息,如标题、列表、表格等重要元素。Microsoft 开源的 MarkItDown 项目就是为解决这一问题而诞生的。它能将各种格式的文档转换为 Markdown 格式,既保留了原文档的结构信息,又保证了输出内容的简洁性,特别适合与 LLM 配合使用。本文将深入探讨 MarkItDown 的功能特点、应用场景和使用方法,帮助开发者更好地利用这一强大工具。
markitdown
MarkItDown now offers an MCP (Model Context Protocol) server for integration with LLM applications like Claude Desktop. See markitdown-mcp for more information.
Python tool for converting files and office documents to Markdown.
主要功能
MarkItDown 的核心功能是将各种文件格式转换为 Markdown,特别强调在转换过程中保留文档结构和内容的完整性。与类似工具如 textract 相比,MarkItDown 更专注于保留文档中的以下结构元素:
- 标题层级
- 列表格式
- 表格结构
- 超链接
- 图像引用
- 文本格式(如粗体、斜体)
支持的文件格式
MarkItDown 支持的文件格式非常丰富,包括:
- PDF 文档
- PowerPoint 演示文稿
- Word 文档
- Excel 电子表格
- 图像文件(包括 EXIF 元数据提取和 OCR 文字识别)
- 音频文件(支持 EXIF 元数据提取和语音转文字)
- HTML 网页
- 各种文本格式(CSV、JSON、XML 等)
- ZIP 压缩文件(自动遍历内容)
- YouTube 视频链接(提取字幕)
- EPub 电子书
- 以及更多…
技术架构
MarkItDown 采用模块化设计,主要包含以下组件:
- 核心转换引擎:负责文件格式识别和转换协调
- 文件格式转换器:针对不同文件格式的专用转换模块
- 插件系统:支持第三方扩展功能
- 命令行接口:便于在终端中使用
- Python API:方便集成到其他 Python 应用中
安装与使用
安装
MarkItDown 可以通过 pip 安装。为了获得完整功能,建议安装所有可选依赖:
| |
如果只需要部分功能,可以选择性安装依赖:
| |
也可以从源代码安装:
| |
可选依赖包
MarkItDown 将依赖组织为可选特性组,当前支持的特性组包括:
[all]:安装所有可选依赖[pptx]:PowerPoint 文件支持[docx]:Word 文件支持[xlsx]:Excel 文件支持[xls]:旧版 Excel 文件支持[pdf]:PDF 文件支持[outlook]:Outlook 邮件支持[az-doc-intel]:Azure Document Intelligence 支持[audio-transcription]:音频转录支持(wav 和 mp3 文件)[youtube-transcription]:YouTube 视频转录支持
命令行使用
最基本的命令行使用方式:
| |
命令行方式
Python API 使用
基本使用:
| |
集成文档智能:
| |
使用大语言模型生成图片描述(当前只适用于 pptx 和 image文件)需要提供 llm_client 和 llm_model:
| |
Azure AI 文档智能是一项基于云的Azure AI 服务,支持构建智能文档处理解决方案。在 Python 代码中使用 MarkItDown:
| |
pdf3md
PDF3MD 是一个现代化、用户友好的网络应用程序,旨在将 PDF 文档转换为干净、格式化的 Markdown 文本。它提供了高效的转换工具,支持多种文件格式之间的转换。
注意:不要用那种扫描的 pdf 文件,毕竟还不支持 ocr 功能
主要特点
- PDF 转 Markdown:能够将 PDF 文档转换为可读性强的 Markdown 格式,同时保留文档的结构元素。
- Markdown 转 Word (DOCX):支持将用户提供的 Markdown 文本转换为 DOCX 格式,使用 Pandoc 实现高质量输出。
- 多文件上传:支持同时上传和处理多个 PDF 文件,提升工作效率。
- 拖拽式界面:提供用户友好的文件上传方式,支持拖放或传统的文件选择。
- 实时进度跟踪:在转换过程中提供详细的状态更新,用户可以实时监控转换进度。
- 现代响应式用户界面:设计直观,适合各种设备使用。
应用场景
- 文档转换:适用于需要将 PDF 文档转换为 Markdown 的用户,例如技术文档编辑、博客撰写等。
- 内容编辑:方便用户在 Markdown 格式下进行内容编辑和格式化,然后可以轻松导出为 Word 文档。
- 批量处理:适合需要处理大量文档的场景,例如教育机构、出版社等。
PDF3MD 通过提供简化的文档转换流程,大大提升了用户的工作效率和体验。
gptpdf
gptpdf 是一个利用VLLM解析PDF为Markdown的工具,几乎完美支持数学公式、表格等。
GPTPDF 是一个使用视觉大模型(如 GPT-4o)将 PDF 文件解析成 Markdown 文件的工具。它主要用于高效地解析 PDF 文档中的排版、数学公式、表格、图片、图表等内容,并将这些内容转换为结构化的 Markdown 格式。其显著特点是简单且成本低,每页平均费用为 $0.013。
地址: https://github.com/CosmosShadow/gptpdf
marker
Marker是一款将PDF快速精准转换为Markdown的工具,支持多种文档格式和语言。
Marker是一款能够快速且准确地将PDF转换为Markdown的工具。它支持多种类型的文档(针对书籍和科学论文进行了优化),支持所有语言,并且能够去除页眉、页脚及其他杂乱信息。此外,它还能正确格式化表格和代码块,并提取图像保存为Markdown。同时,Marker将大多数的公式转换为LaTeX格式,适用于GPU、CPU或MPS环境。
地址: https://github.com/vikparuchuri/marker
PDF-Extract-Kit
PDF-Extract-Kit 提供高质量PDF内容提取,支持布局检测、公式识别和OCR功能
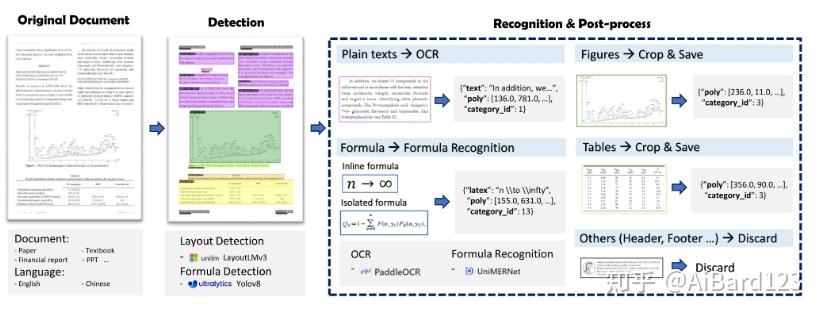
基本功能:
- 版面检测:使用 LayoutLMv3 模型进行区域检测,如检测图片、表格、标题、文本等。
- 公式检测:使用 YOLOv8 模型检测公式,包括行内公式和独立公式。
- 公式识别:使用 UniMERNet 进行公式识别。
- 光学字符识别 (OCR):使用 PaddleOCR 进行文本识别。
地址: https://github.com/opendatalab/PDF-Extract-Kit
zeroX
Zerox OCR 是一种经济高效且准确的文档OCR工具,适用于AI数据处理。
Zerox OCR 是一种极其简便的方法,用于将文档进行光学字符识别(OCR)并方便人工智能进行后续处理。鉴于文档往往包含复杂布局、表格、图表等,视觉模型在处理这些内容时尤其有效。
基本逻辑如下:
- 提供一个 PDF 文件(URL 或文件缓冲区)。
- 将 PDF 转换成一系列图像。
- 将每个图像传给 GPT,让其生成 Markdown 格式的文本。
- 聚合所有响应,并返回 Markdown 格式的结果。
地址: https://github.com/getomni-ai/zeroX
omniparse
OmniParse是一个将各种非结构化数据转换为结构化、适用于生成式AI(LLM)应用的平台。

OmniParse 是一个数据解析平台,旨在将各种非结构化数据转换为适用于生成式AI(GenAI)应用的结构化数据。无论是文档、表格、图像、视频、音频文件,还是网页,OmniParse 都能对其进行处理,使其变得干净、结构化,并为诸如 RAG(Retrieval-Augmented Generation)和细调等AI应用做好准备。
特色:
- 完全本地化,无需外部API
- 支持多达 20 种文件类型
- 将文档、多媒体和网页转换为高质量的结构化 Markdown
- 支持表格提取、图像提取与标注、音频/视频转录、网页爬取
- 通过 Docker 和 Skypilot 轻松部署
- 兼容 Colab
- 交互式 UI 由 Gradio 提供支持
地址: https://github.com/adithya-s-k/omniparse
MinerU
MinerU 是一个开源的高质量数据提取工具,支持多种文件格式

MinerU 是一个一站式、开源的高质量数据提取工具,主要包括以下两个核心功能模块:
功能介绍:Magic-PDF 能将 PDF 文档转换为 Markdown 格式,可以处理本地存储或支持 S3 协议的对象存储中的文件。
主要特色:
- 支持多种前端模型输入
- 自动去除页眉、页脚、脚注和页码
- 保留文档原有的结构和格式,包括标题、段落、列表等
- 提取并显示图片和表格
- 将公式转换为 LaTeX 格式
- 自动检测和转换乱码 PDF 文档
- 兼容 CPU 和 GPU 环境
- 可在 Windows、Linux 和 macOS 平台上使用
地址: https://github.com/opendatalab/MinerU