T5 结构及应用
在前两节中,我们分别学习了基于 Encoder 的 BERT(擅长理解)和基于 Decoder 的 GPT(擅长生成)。那 Transformer 最原始的 Encoder-Decoder 结构去哪了?
本节的主角 T5 (Text-to-Text Transfer Transformer) 1 回归了这一经典架构。BERT 擅长理解(如分类、实体识别),GPT 擅长生成(如续写、对话),而 T5 则试图在输入输出形式上寻找一种通解。如图 5-5,它将所有 NLP 任务都视为 “文本到文本” (Text-to-Text) 的转换问题,以此来统一处理理解与生成任务。
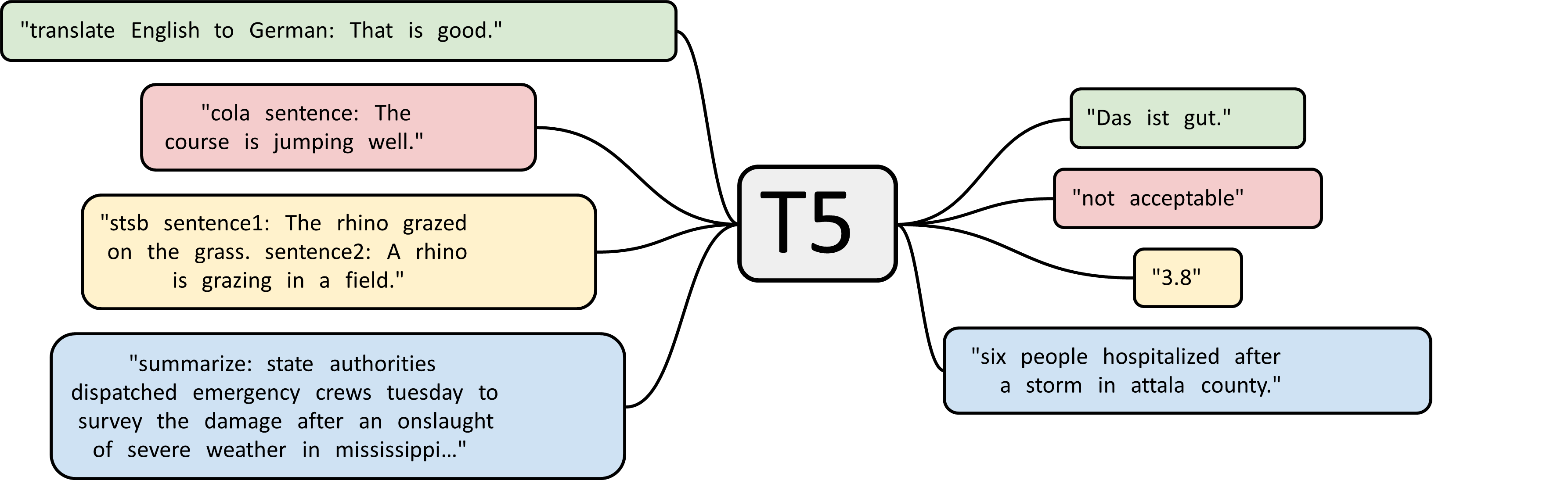
图 5-5 Text-to-Text 框架示意图
一、万物皆文本的核心理念
在 BERT 模式下,针对不同的任务,我们需要设计不同的模型结构:
- 文本分类:BERT + 全连接层(分类头)。
- 序列标注:BERT + CRF/分类层。
- 文本相似度:双塔 BERT 或拼接输入 + 回归层。
Google 提出的 T5 模型打破了这种模式。它提出——无论是什么任务,输入是文本,输出也是文本。我们以《黑神话:悟空》的评论处理为例:
- 翻译:输入 “翻译成英文: 黑神话悟空真好玩” -> 输出 “Black Myth: Wukong is really fun.”
- 情感分类:输入 “情感分析: 黑神话悟空真好玩” -> 输出 “正面”
- 摘要:输入 “摘要: 黑神话悟空是一款以中国神话为背景的动作角色扮演游戏…” -> 输出 “黑神话悟空是国产 3A 动作游戏。”
- 回归(打分):输入 “计算相似度 句子1: 黑神话悟空真好玩 句子2: 这猴子游戏真不错” -> 输出 “4.5” (直接生成数字文本)
1.1 提示词的先驱与多任务平衡
为了让同一个模型能够区分不同的任务,T5 引入了 Task Prefix (任务前缀) 的概念。例如,在做翻译时,我们在输入文本前加上 翻译成英文:;在做摘要时,加上 摘要:。
这其实就是大语言模型时代提示词的雏形。虽然同期的 GPT-2 也展示了类似的续写能力,但 T5 是较早系统化地将“使用自然语言指令显式定义任务”这一范式应用到大规模预训练与多任务设置中的模型之一。它证明了我们可以通过改变输入文本(Instruction)来“编程”模型,而不仅仅是改变模型结构。
T5 Prefix 与 GPT Prompt 的区别
虽然两者看起来很像,但出发点不同:
- T5 Prefix:主要用于有监督微调。模型在训练时就见过这些前缀,它们是“多任务学习”的一种标记,告诉模型当前要调动哪部分参数。
- GPT Prompt:主要用于零样本/少样本推理。模型在预训练时可能没见过特定的 Prompt,但依靠强大的泛化能力,它能通过 Prompt 理解用户的意图,而无需更新参数。
在有监督训练阶段,T5 将多个任务统一为一个多任务学习(Multi-task Learning)框架。由于不同任务(如翻译、摘要、分类)的数据量差异巨大,如果简单混合,大任务会淹没小任务。T5 采用了一种带有上限的比例混合策略(对大数据集设置采样上限、适当提升小数据集的采样概率),确保模型能“雨露均沾”地学习各种能力。
1.2 独特的预训练目标 Span Corruption
不同于 BERT 的“单字掩码”(Masked LM)或 GPT 的“单向预测”(Causal LM),T5 为了适应 Encoder-Decoder 结构,设计了一种如图 5-6 所示的全新预训练目标——Span Corruption(片段破坏与重构)。
- 破坏:在输入文本中随机选中一些连续的片段(Span),并将它们替换为特殊的哨兵符(Sentinel Token),如
<extra_id_0>,<extra_id_1>。 - 重构:要求 Decoder 生成被遮盖的片段。

图 5-6 Span Corruption 预训练目标示意图
关键设计细节:
- Mask 比例与长度:T5 经过大量实验发现,遮盖 15% 的 token,且平均片段长度为 3 时,模型性能最佳。这比 BERT 仅遮盖单个 token 更有挑战性,会迫使模型理解更长的上下文依赖。
- 哨兵符的唯一性:输出序列中包含的
<extra_id_0>等哨兵符是唯一的,不与词表中的普通词共享。这让 Decoder 能够精确地定位它正在恢复的是哪一段内容。
示例:
- 原始文本:
黑神话悟空是一款以中国神话为背景的动作角色扮演游戏。 - 输入 (Encoder):
黑神话悟空是一款<extra_id_0>的动作<extra_id_1>游戏。 - 输出 (Decoder):
<extra_id_0>以中国神话为背景<extra_id_1>角色扮演<extra_id_2>
输出末尾的
<extra_id_2>起到了结束符的作用,表示所有被遮盖的片段都已恢复完毕。
这种预训练任务兼顾了理解(Encoder)与生成(Decoder)。配合 T5 使用的 C4 (Colossal Clean Crawled Corpus) 超大规模清洗数据集,模型学习到了极其丰富的语言知识。
二、T5 架构解析
2.1 回归经典的模型结构
T5 的整体架构与原始 Transformer 几乎一致,是一个标准的 Encoder-Decoder 模型:
- Encoder:负责理解输入文本(如 BERT)。
- Decoder:负责自回归地生成输出文本(如 GPT)。
这种结构使得 T5 既具备 BERT 的双向理解能力,又具备 GPT 的生成能力,完美契合 “Text-to-Text” 的任务设定。
2.2 关键技术改进
虽然宏观结构回归经典,但在微观层面,T5 引入了多项针对大模型训练优化的“黑科技”,这些改进后来也成为了许多现代大模型(如 PaLM, LLaMA)的标配。
1. 相对位置编码
在 BERT 和 GPT 中,使用的是绝对位置编码(给每个位置分配一个固定的向量)。但 T5 认为,注意力机制应该关注词与词之间的相对距离,而不是它们在句子中的绝对坐标。
T5 采用了一种基于分桶 (Bucketing) 的相对位置编码方案:
- 近距离精确,远距离模糊:对于相邻的词(如距离 < 8),模型会精确区分它们的距离;对于较远的词(如距离 > 8),模型通过对数映射将它们归入同一个“桶”中。
- 参数共享:位置编码不再是加在 Input Embedding 上,而是作为 Bias (偏置) 直接加在 Attention Score (Q·K) 矩阵上。并且,这些位置编码的参数在所有层之间共享,即每一层都使用相同的一组 Bias 参数,大幅减少了参数量。
2. 简化版 Layer Normalization
T5 使用了一种简化版的层归一化(Layer Normalization)。与标准 LayerNorm 不同,T5 去除了加性偏置 (Additive Bias),仅对激活值进行缩放(Rescaling)。这种设计在保证性能的同时,减少了参数量和计算开销。
此外,原版 T5 在前馈网络(FFN)中使用的仍是标准的 ReLU 激活函数。直到后续的 T5 v1.1 版本,才引入了更复杂的 GEGLU 门控激活单元。
3. SentencePiece 分词器
与 BERT 使用 WordPiece、GPT 使用 BPE 不同,T5 采用了 SentencePiece 分词器。
- 处理原始文本:BERT 需要先将文本进行预分词(Pre-tokenization,如按空格切分),这对于中文或不使用空格的语言并不友好。T5 的 SentencePiece 直接在**原始文本(Raw Text)**上进行训练,将空格视为一种特殊字符(如
_)处理。 - 语言无关性:这种设计使得 T5 能够天然地支持多语言混合训练,而不需要针对每种语言设计特定的分词规则,非常符合其“大一统”的设计哲学。
三、T5 代码实战
我们使用 transformers 库来加载 T5 模型,并深入观察其相对位置编码的实现细节。
3.1 Text-to-Text 任务演示
| |
输出:
| |
可以看到,T5 能够通过不同的任务前缀(translate..., stsb...)灵活地切换模式。特别是第二个例子,T5 并不是像 BERT 那样输出一个回归数值,而是直接生成了字符串 "4.0"。这就体现了它“万物皆文本”的设计哲学——无论是翻译、分类还是数值预测,最终都统一为文本生成任务。
如果把
translate English to German换成translate English to Chinese会发现模型依然输出了德语。这是因为原版 T5 在训练时,只包含英语到德语、法语、罗马尼亚语等少数语种的翻译任务,并没有专门的英语到中文翻译任务指令。它的词表主要基于英文及相关翻译语料,几乎不包含中文字符。对于模型来说,它只是机械地匹配到了translate English to这个模式,然后按照训练中形成的“翻译任务”分布,倾向于生成在这类任务里最常见的目标语种之一——德语,而不会真正去“理解”Chinese这个词。如果要处理中文任务,需要使用支持 101 种语言的 mT5 模型 2。
3.2 相对位置编码分桶逻辑源码解析
在 transformers 库实现的 T5 源码中,相对位置编码并没有像 BERT 那样作为 Input Embedding 的一部分,而是在 Attention 层计算 Attention Score 时,作为一个偏置项(Bias)加进去的。
我们通过 transformers 库中 T5Attention 类的 compute_bias 方法可以完整看到这一过程。
compute_bias主要用于预计算或缓存 Bias,虽然在训练时的前向传播(forward)中不一定直接调用它,但它封装了从“位置索引”到“最终 Bias 矩阵”的完整逻辑链条,适合作为理解原理的切入点。
| |
原理解析:
- 解耦位置与内容:BERT 将位置信息加在 Input Embedding 上,意味着位置和内容在第一层就混合了。而 T5 选择在每一层 Attention 计算时,直接在这个 $N \times N$ 的注意力分数矩阵上加上一个位置偏置矩阵(Bias),让位置信息更直接地作用于注意力权重。
- 参数效率:如果为每个距离都学习一个 Bias,参数量会太大。T5 通过**分桶(Bucketing)**策略,将无限的距离映射到有限的桶(如 32 个)中,大大减少了参数量。
- 对数映射:分桶时采用“近密远疏”的策略(对数映射),因为人类语言对近距离的语法依赖(如主谓关系)非常敏感,需要精确区分;而对于远距离的语义依赖,只需要知道“大概很远”就足够了。
下面我们将 compute_bias 中调用的核心分桶函数 _relative_position_bucket 单独提取出来,并编写一段简单的测试代码,来看看相对距离是如何被映射为 Bucket ID 的:
| |
输出:
| |
结果分析:
- 双向区分:可以看到,距离为
0(自己关注自己) 映射为0。正向距离(如1, 5, 10)和负向距离(如-1, -5, -10)被映射到了不同的区间(正向从 16 开始,负向在 0-15 之间),说明 T5 在 Encoder 中区分了“左边”和“右边”。 - 近密远疏:
- 近距离如
0和1分别对应桶0和17,每个距离都有独立的桶。 - 远距离如
50和100,虽然数值相差很大,但桶号29和31却很接近。这就是对数映射的效果——距离越远,分桶越粗糙。
- 近距离如
这段代码体现了 T5 设计者的巧思。人类语言对近距离的依赖非常敏感(如主谓搭配),需要精确建模;而对于远距离的依赖,只需要知道“大概很远”就足够了。这种设计既捕捉了长距离信息,又有效节省了模型参数,实现了性能与效率的平衡。